布铃酱的点心铺
好朋友们
 HAUE_LYS' Blog
HAUE_LYS' Blog
 秋萤blog-秋秋的点心铺
秋萤blog-秋秋的点心铺
 赤城的部落格
赤城的部落格
 Arnoya's Blog
Arnoya's Blog
 Jinze 's Blog
Jinze 's Blog
 Chains Space
Chains Space
 Zwanan's Blog
Zwanan's Blog
 梦璃魔女的魔法笔记
梦璃魔女的魔法笔记

工具推荐
文章最后更新:2024-09-15

记录我电脑上必备的一些实用工具推荐,附上官方下载地址。
系统信息查看和优化
AIDA64
下载安装
https://www.aida64.com/downloads
Autoruns
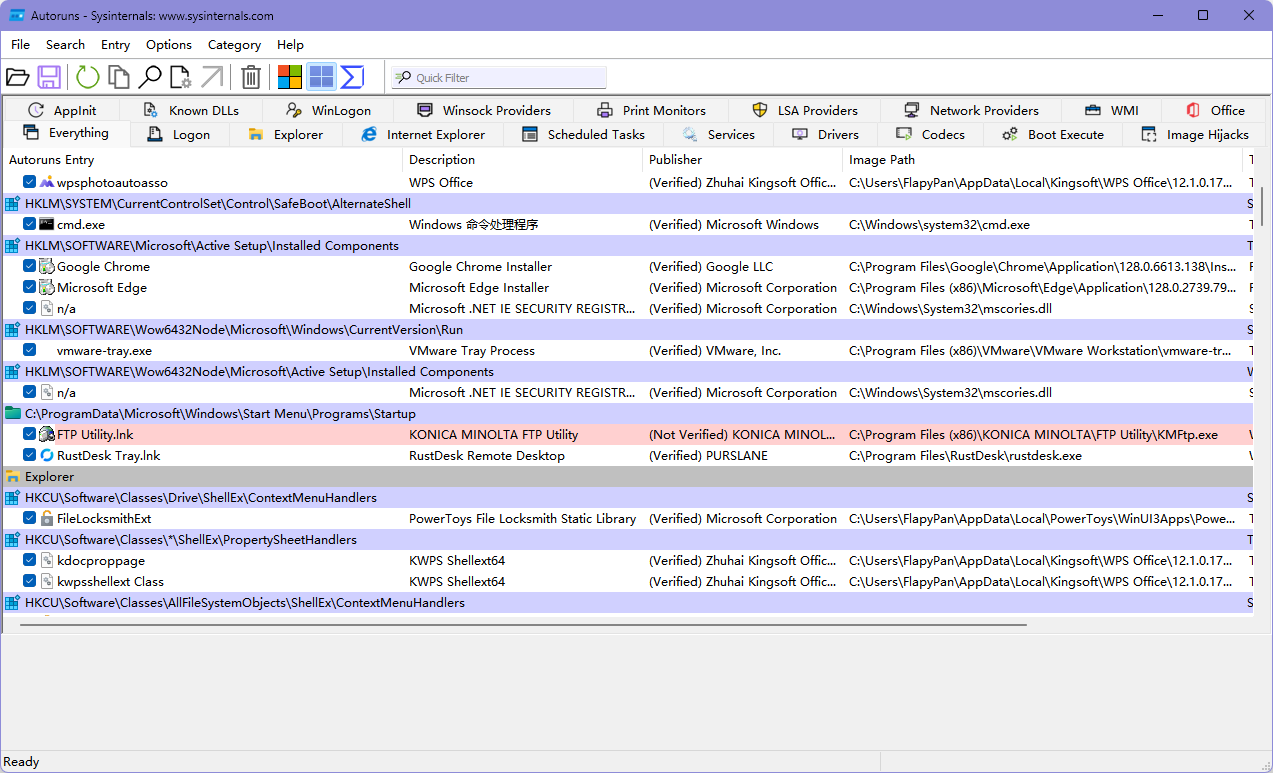
此实用工具对任何启动监视器的自动启动位置都有最全面的了解,它显示在系统启动或登录期间,以及在启动各种内置 Windows 应用(如 Internet Explorer、Explorer 和媒体播放器)时,配置为运行哪些程序。 这些程序和驱动程序包含在启动文件夹、Run、RunOnce 和其他注册表项中。 Autoruns 报告 Explorer 外壳扩展、工具栏、浏览器帮助程序对象、Winlogon 通知、自动启动服务等等。
下载安装
微软官网安装:https://learn.microsoft.com/zh-cn/sysinternals/downloads/autoruns#download
Defender Control
彻底关闭自带杀毒软件,win10、win11 都可用.
下载安装
去 sordum 官网搜索下载,他们有很多实用小工具都可以去下载试试:https://www.sordum.org/
Windows Update Blocker
关闭更新服务的工具。
下载安装
去 sordum 官网搜索下载,他们有很多实用小工具都可以去下载试试:https://www.sordum.org/
DXVA Checker
检查支持的编解码器。
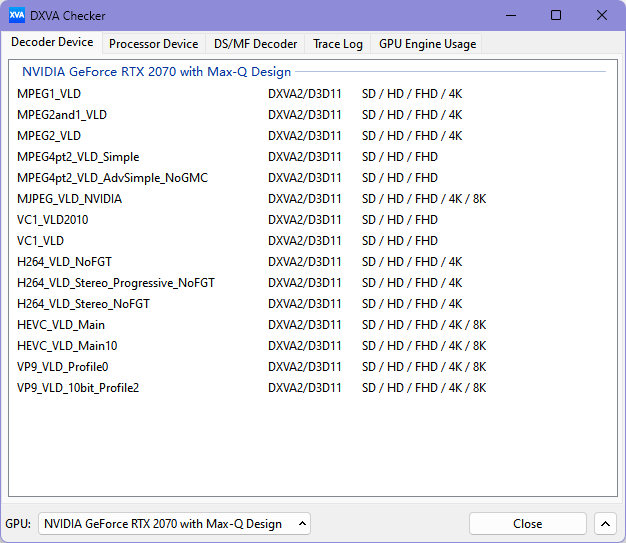
下载安装
https://bluesky-soft.com/en/DXVAChecker.html
NatTypeTester
检查当前网络的 nat 类型。
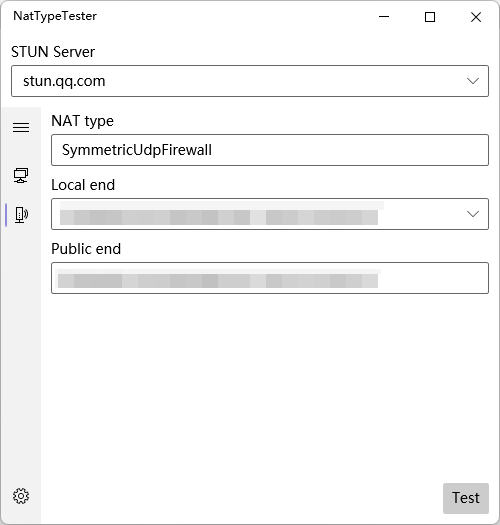
源码仓库
https://github.com/HMBSbige/NatTypeTester
noMeiryoUI
换字体。
源码仓库
https://github.com/Tatsu-syo/noMeiryoUI
Optimizer
一些优化工具。
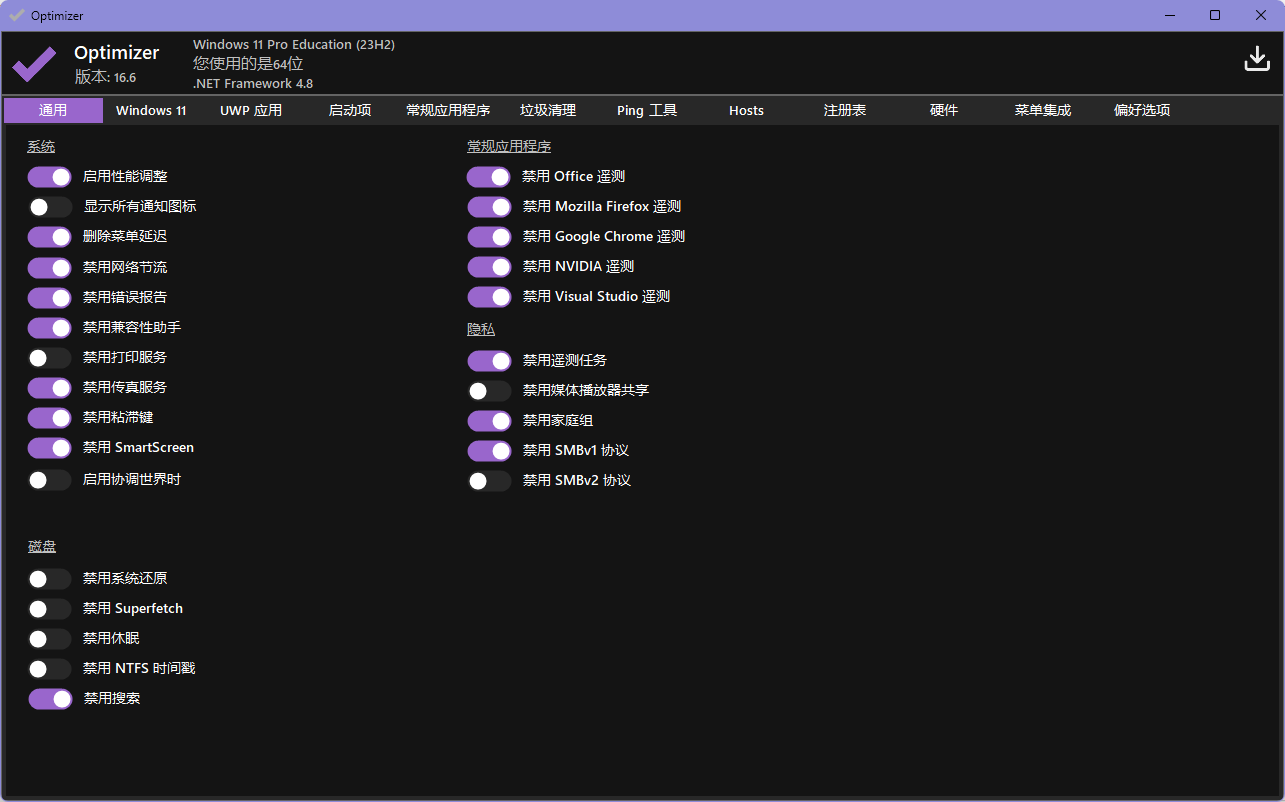
源码仓库
https://github.com/hellzerg/optimizer
ProcessExplorer
查看和管理进程的工具。
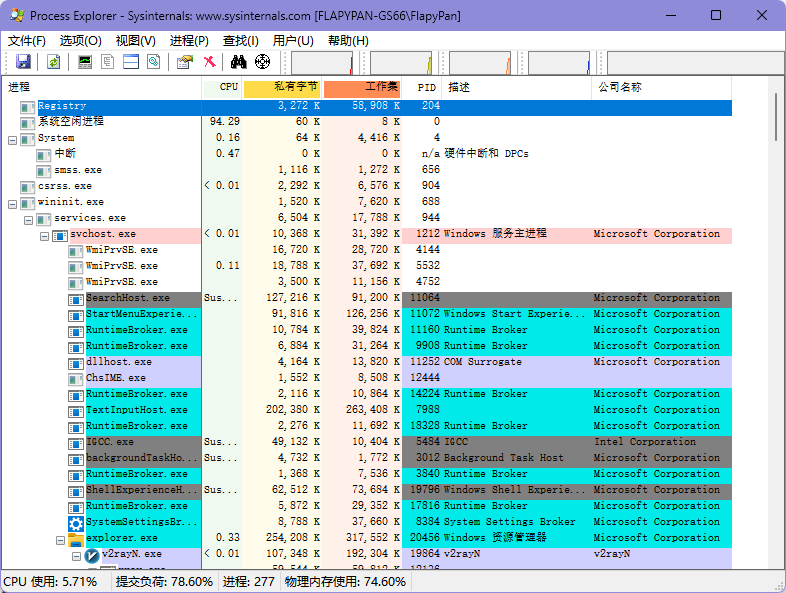
下载安装
微软https://learn.microsoft.com/zh-cn/sysinternals/downloads/process-explorer
PowerSettingsExplorer
调整电源配置的工具,可以调整大小核心优先度。
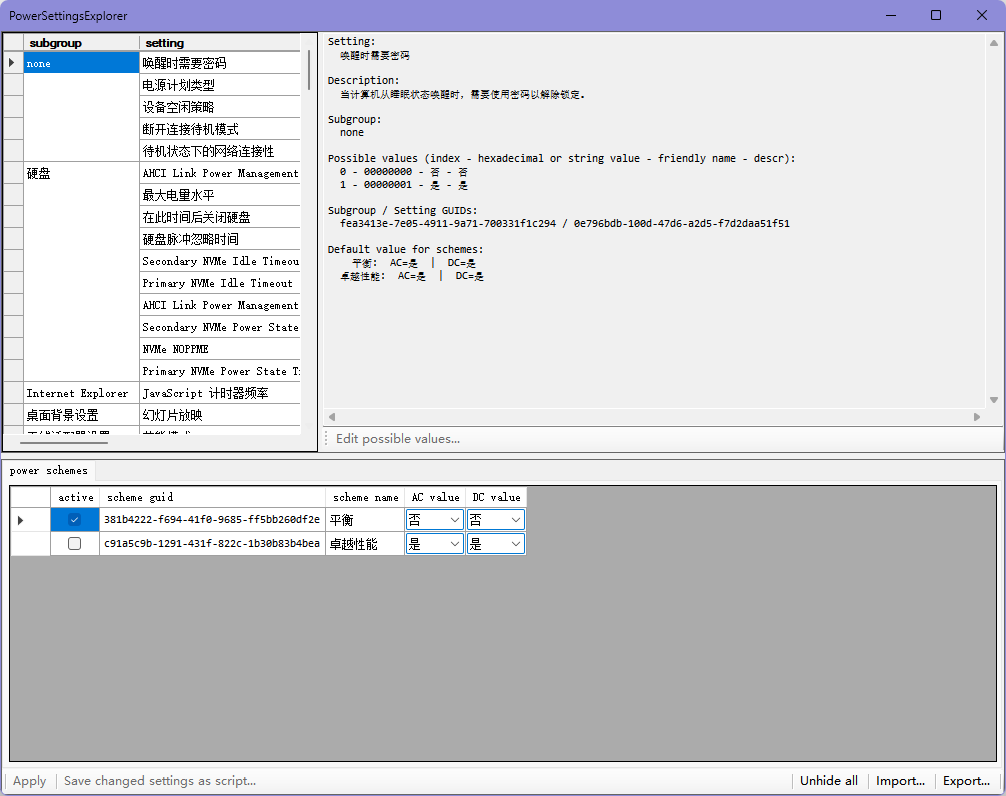
下载安装
坏了,我自己都找不到在哪下的了,有需要的可以联系我。
Runasdate
伪装日期时间运行程序,可能对一些限时试用软件有奇效?
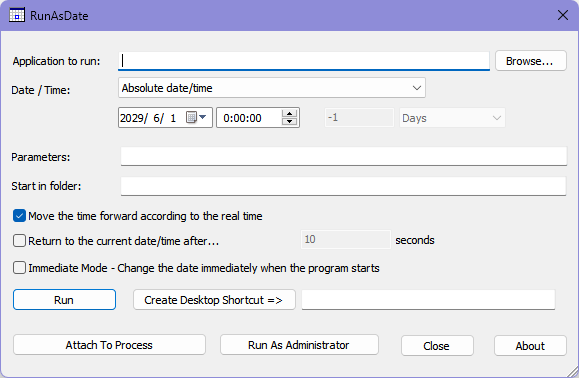
下载安装
https://www.nirsoft.net/utils/run_as_date.html
Windows11Manager
一些优化工具。

下载安装
https://www.yamicsoft.com/cn/index.html
CompactGUI
Windows Compact 功能的图形化工具。
源码仓库
https://github.com/IridiumIO/CompactGUI
ContextMenuManager
右键菜单管理工具。
仓库地址
https://github.com/BluePointLilac/ContextMenuManager
InSpectre
幽灵漏洞修复微码的开启和关闭工具。
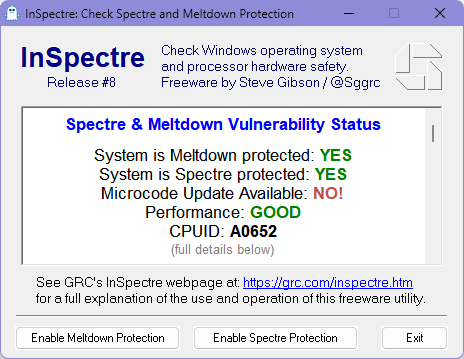
下载安装
https://www.grc.com/inspectre.htm
软件屏蔽器 MWP
源码仓库
https://github.com/the1812/Malware-Patch
TCPOptimizer
网络优化工具。
下载安装
https://www.speedguide.net/downloads.php
磁盘和PE工具
Ventoy
非常好 PE 工具,使我的 ISO 旋转。
想起我在机房用这个玩意装系统的日子了
下载安装
https://www.ventoy.net/cn/download.html
Bootice64
下载安装
https://www.majorgeeks.com/files/details/bootice_64_bit.html
CrystalDiskInfo
下载安装
https://crystalmark.info/en/software/crystaldiskinfo/
卸载和清理工具
Bulk Crap Uninstaller (BCU)
下载安装
https://www.bcuninstaller.com/
Geek Uninstaller
下载安装
https://geekuninstaller.com/download
Dism++
源码仓库
https://github.com/Chuyu-Team/Dism-Multi-language
娱乐
CentBrowser (4.1.7.182)
这个版本(4.1.7.182)附带了 Flash 插件,可以玩一些老的 4399 小游戏,推荐用便携版。
下载安装
https://www.centbrowser.com/history.html#4.1.7.182
其他
TorBrowser
都懂。
Claude Code 穷鬼方案
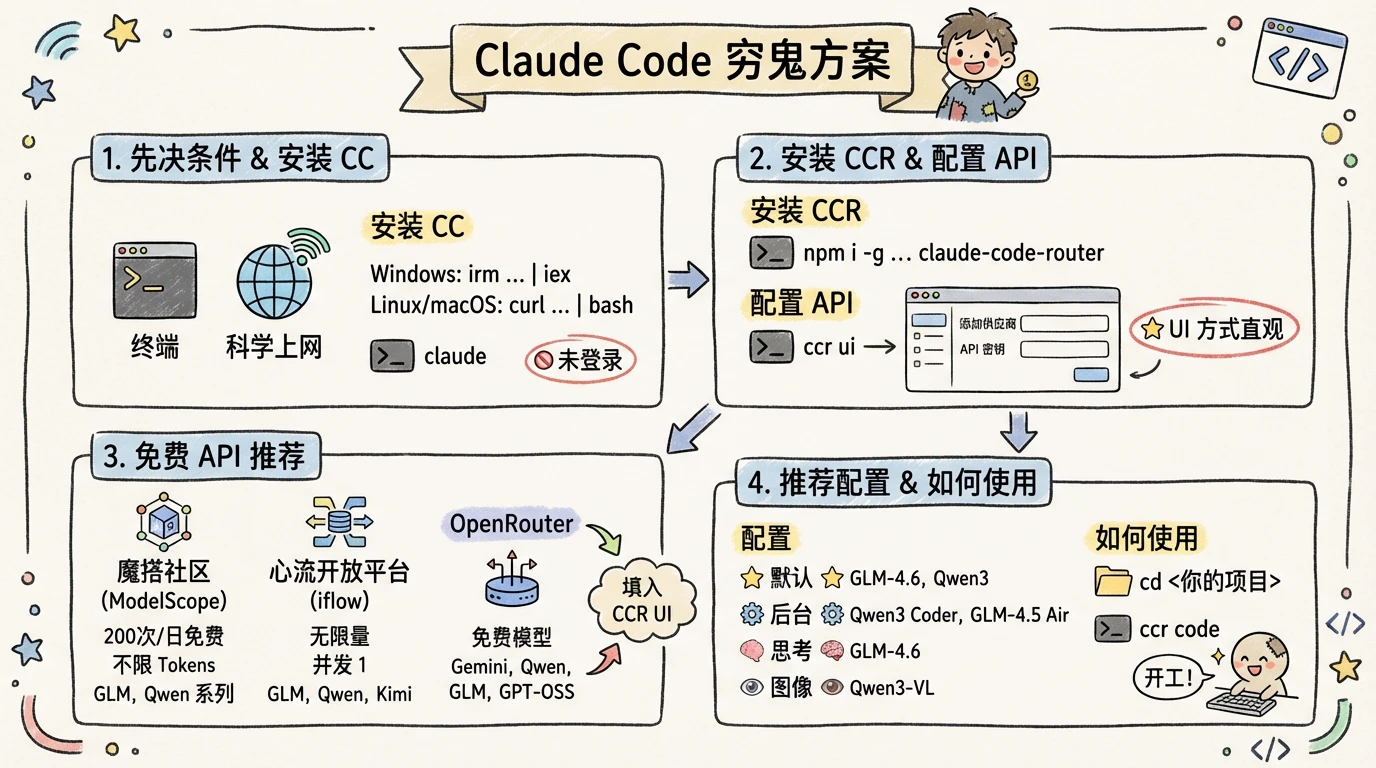
文章最后更新日期:2025-11-18
分享下我的一套穷人使用 Claude Code 的方案
写在前面
注意这套方案只是把 Claude Code(以下简称 cc)的 api 换成免费的其他模型
Claude 模型确实贵啊
目前 Claude Code 是业内顶尖的编程 Agent,哪怕换了开源模型也能发挥出非常强的实力
说的就是你 trae,模型不差但是配了个稀烂的工具
先决条件
- 好用的终端软件,Windows 11 推荐直接使用内置的
终端软件 - 科学上网
Claude 一般指 Anthropics 公司旗下的模型
Claude Code 是 Anthropics 开发的终端编码 Agent
安装 Claude Code
Claude Code 官网:https://claude.com/product/claude-code
Claude Code 官方文档:https://docs.claude.com/en/docs/claude-code/overview
使用下面指令安装或更新 cc
Windows 在 PowerShell 下执行:
irm https://claude.ai/install.ps1 | iex
Linux、WSL、macOS 在命令行执行:
curl -fsSL https://claude.ai/install.sh | bash
安装好后启动一次看是否正常:
claude
因为我们没有登录 Anthropics 账号此时还用不了 cc,我们需要在后续步骤替换为自己的 API
安装 Claude Code Router
Claude Code Router(以下简称ccr)是一个帮助我们将 cc 的请求代理到自定义 API 的开源项目
使用下面指令安装或更新 cc:
npm i -g @musistudio/claude-code-router@latest
或使用镜像:
npm --registry=https://registry.npmmirror.com i -g @musistudio/claude-code-router@latest
配置 API
配置 ccr 有配置文件和 ui 两种方式,推荐使用 ui 方式比较直观
在命令行中输入:
ccr ui
ccr 会在后台运行,并自动打开浏览器访问 http://127.0.0.1:3456/ui/ 配置界面
下面是我已经配置好的
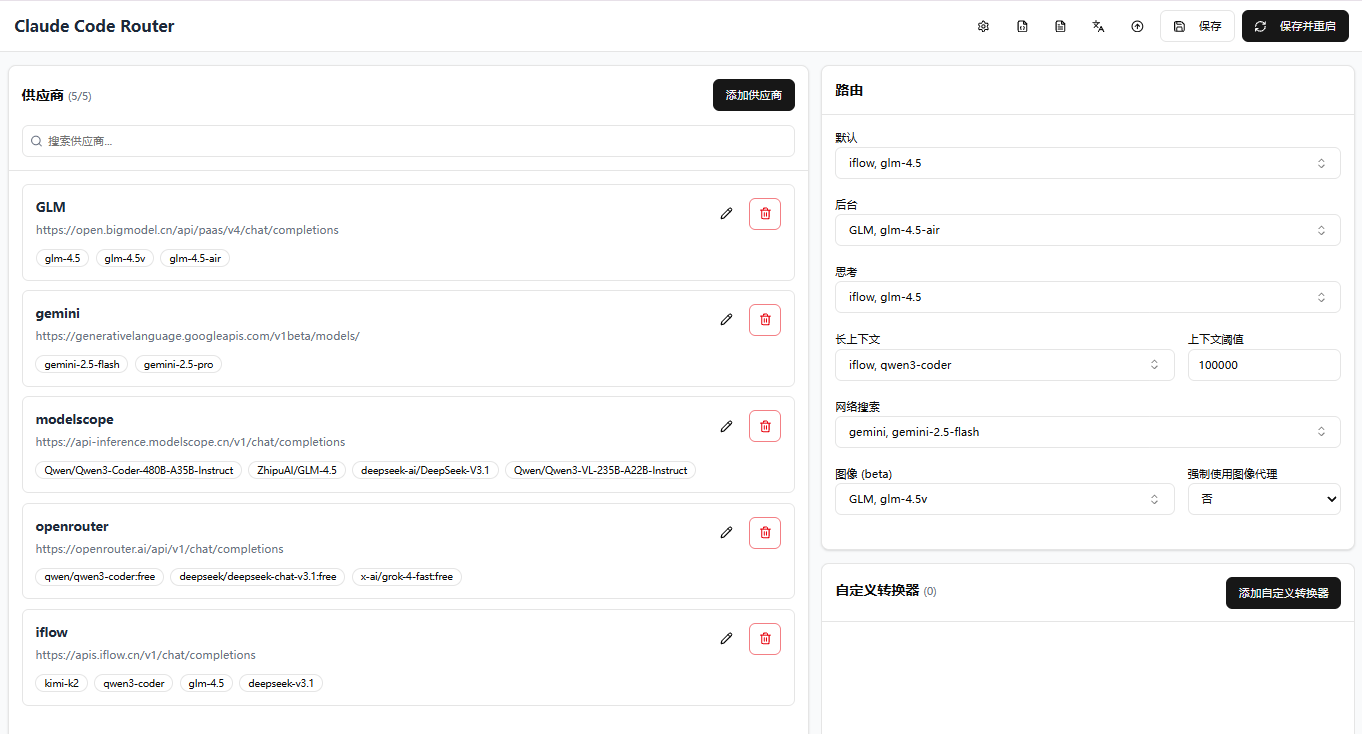
一些免费的 API
一般情况下,添加一个魔搭社区的 api 就足够使用了
魔搭社区
魔搭社区目前每天有每个模型 200 次免费额度,2000 次总额度,不限制 tokens 数量
注册后在账号设置 https://modelscope.cn/my/accountsettings 进行实名认证
在访问令牌 https://modelscope.cn/my/myaccesstoken 页面新建一个新的令牌并复制备用
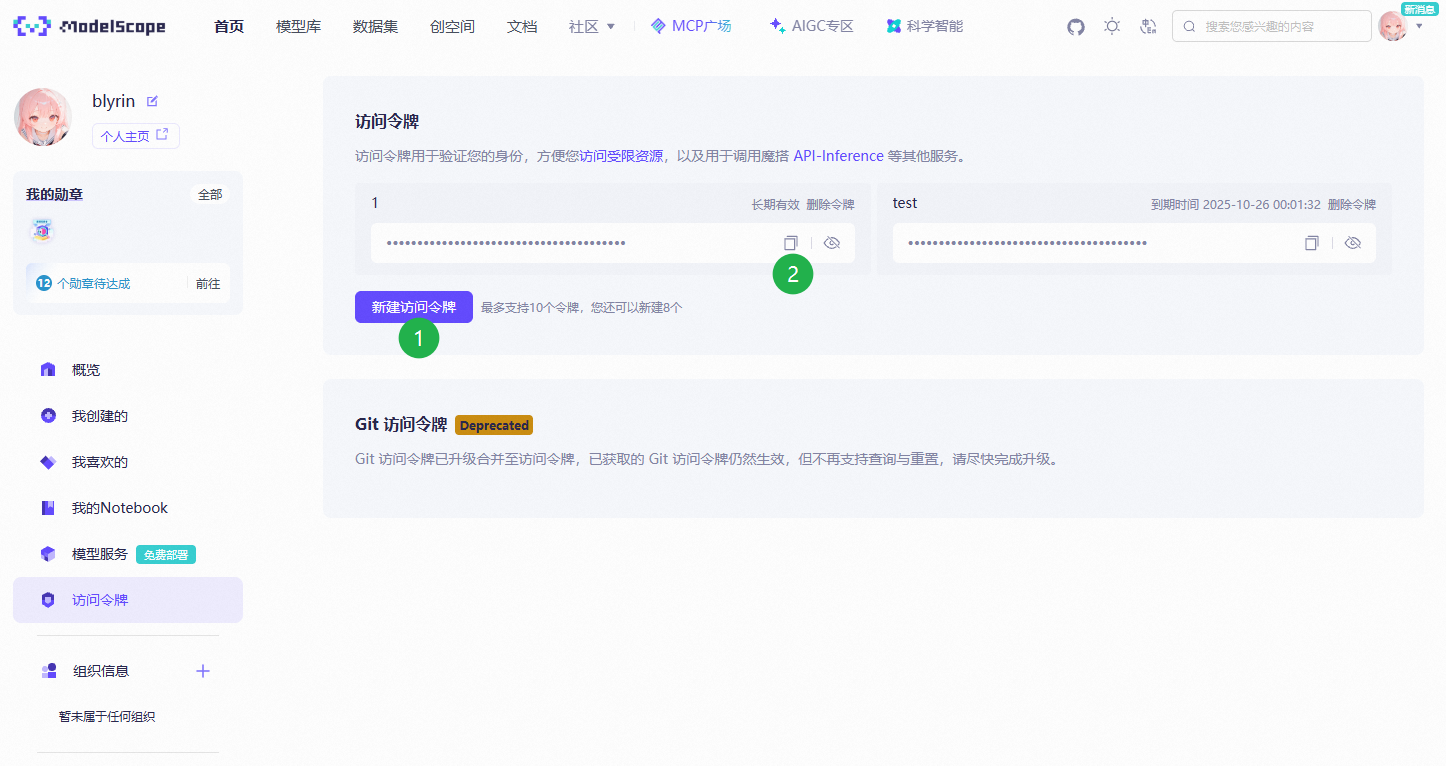
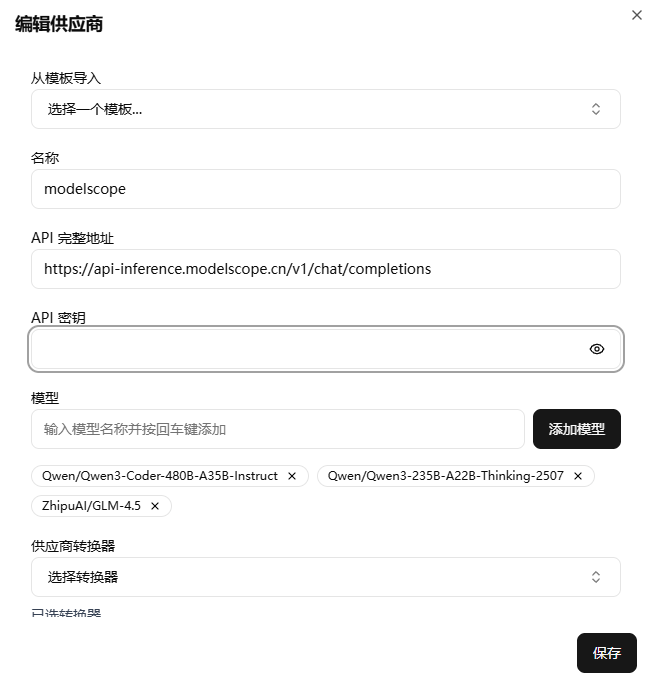
回到 ccr 的 ui 配置页面,点击添加供应商,从模板导入选择 modelscope 并在 API 密钥输入刚才复制的令牌
模型推荐使用 GLM 系列模型,可以在魔搭社区的模型库筛选可以免费使用的模型
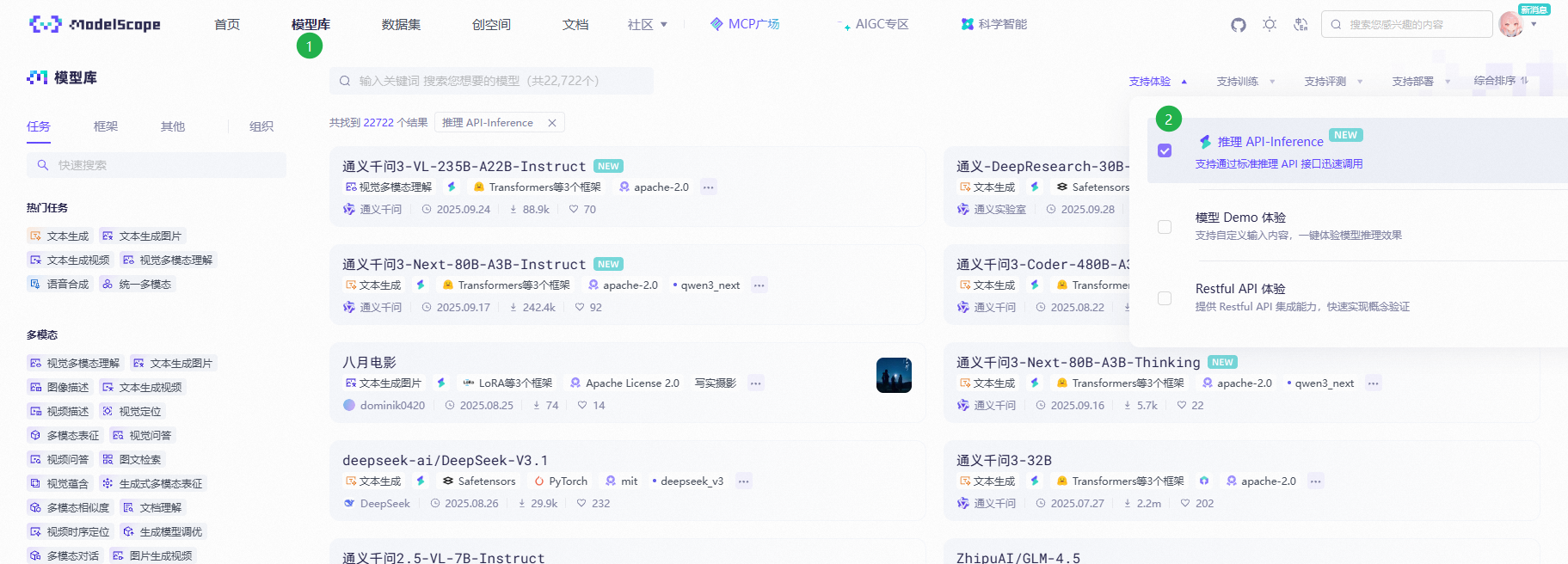
进入模型详情页后复制模型 ID 填到 ccr ui 配置的模型列表中
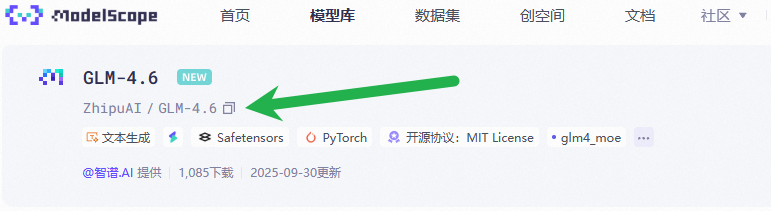
推荐添加的模型 ID:
- ZhipuAI/GLM-4.6(默认)
- Qwen/Qwen3-VL-235B-A22B-Instruct(视觉)
- Qwen/Qwen3-Coder-480B-A35B-Instruct(后台)
- Qwen/Qwen3-235B-A22B-Instruct-2507(后台)
心流开放平台
心流开放平台目前每天无限量调用,但并发次数只有 1(同一个账号只能有一个请求在进行,只要不用作后台模型即可)
注册后在 API Key 设置 https://platform.iflow.cn/profile?tab=apiKey 添加密钥并复制
回到 ccr ui 设置,添加供应商选择模板 iflow
模型 ID 可以在模型库 https://platform.iflow.cn/models 直接复制
推荐添加的模型 ID:
- glm-4.6(默认)
- qwen3-vl-plus(视觉)
- qwen3-coder-plus(默认)(长上下文)
- kimi-k2-0905(默认)
OpenRouter
openrouter 注册后可用使用一些免费的模型
密钥管理:https://openrouter.ai/settings/keys
免费生文模型列表:https://openrouter.ai/models?fmt=table&max_price=0&output_modalities=text
推荐添加的模型 ID:
- google/gemini-2.0-flash-exp:free(网络搜索)
- z-ai/glm-4.5-air:free(后台)
- qwen/qwen3-coder:free(后台)
- openai/gpt-oss-120b:free(后台)
硅基流动
硅基流动目前免费的 API 可用的模型都是小参数的,不适合编码,有需要可自行了解
谷歌 AI Studio
官网:https://aistudio.google.com/
需要科学上网且限制地区
谷歌有免费的 Gemini 模型,但目前不太稳定经常断流,有需要可自行了解
gemini 在 cc 里经常不会调用工具
推荐的配置
配置说明:
- 默认:默认模型,顾名思义
- 后台:执行后台任务,如搜索文件、执行命令行等轻量任务时使用,推荐使用小参数模型
- 思考:思考场景使用的模型,需要模型支持思考
- 长上下文:对话上下文非常长时会自动切到该模型,推荐使用上下文长的模型
- 上下文阈值:切换模型的阈值,默认即可
- 网络搜索:使用模型内置联网搜索功能,需要模型支持
- 图像:识别图片的模型,需要模型支持视觉
下列配置是根据我个人使用情况总结出来的(截至文章最后编辑日期),请根据自己项目的实际情况选择
不加参数说明默认为最大参数型号,模型信息可在 https://models.dev/ 查询
目前并不推荐使用 DeepSeek 系列写代码,
有点蠢
最简配置
- 默认:glm 4.6、qwen3 coder plus、kimi k2 0905
- 后台:glm 4.5 air、qwen3 coder、qwen3、gpt oss 120B
完整配置
- 默认:glm 4.6、qwen3 coder plus、kimi k2 0905
- 后台:glm 4.5 air、qwen3 coder、qwen3、gpt oss 120B
- 思考:glm 4.6
- 长上下文:qwen3 max、glm 4.6、kimi k2 0905、qwen3 coder plus
- 网络搜索:推荐内置网络搜索的 gemini flash、gemini flash lite
- 图像(根据需要):qwen3 vl (plus)、glm 4.5v
如何使用
配置完成后记得保存
# 进入项目目录
cd <你的项目>
# 使用 ccr 启动 cc
ccr code
安装使用 Scoop
文章最后更新:2023-01-10
Windows 下管理软件的小工具。
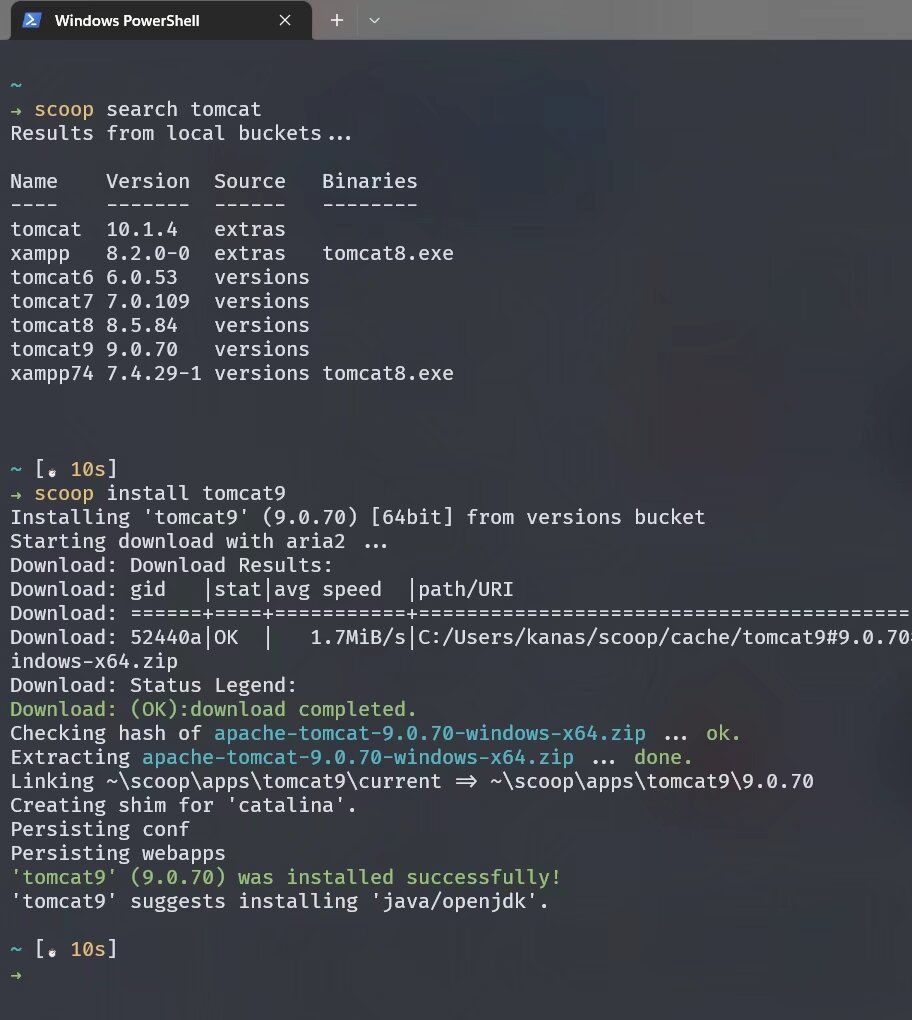
举个例子,安装 tomcat:
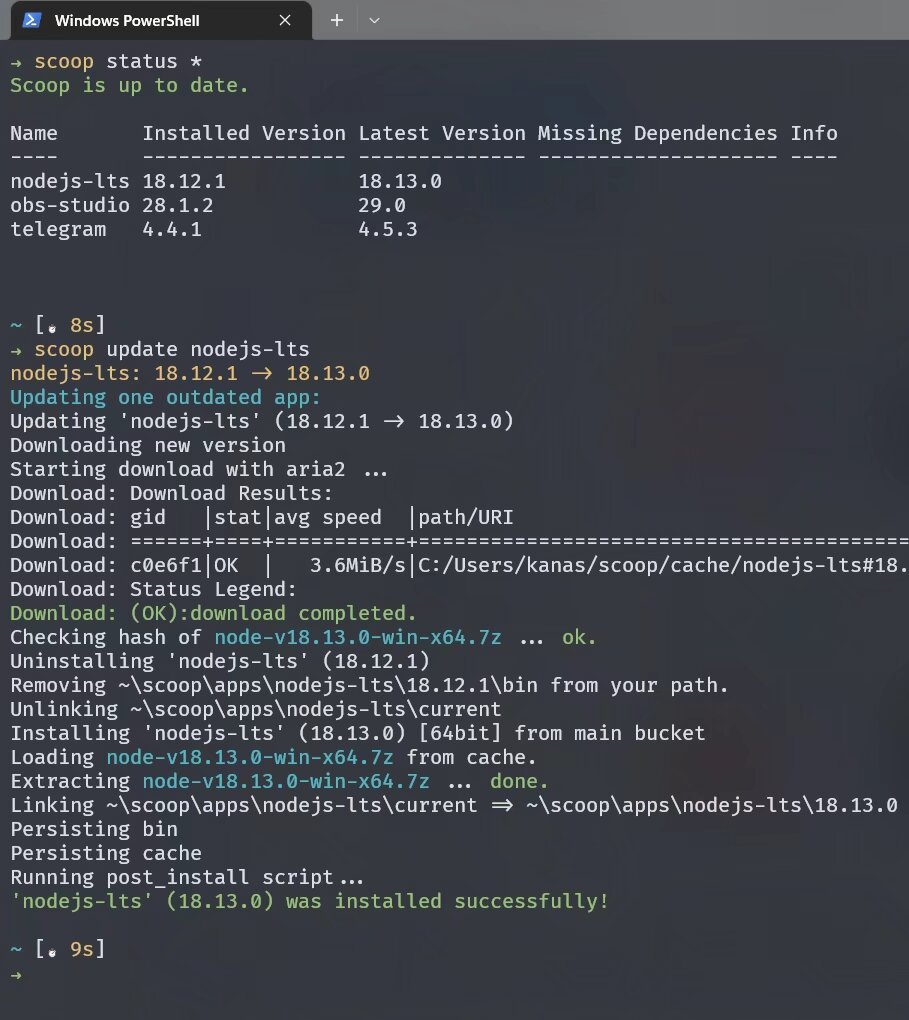
更新软件:
安装和配置
安装
确保你能流畅访问 GitHub。 不要使用国内的一些 Gitee 的代理仓库安装主程序,问题很多!!!
scoop 默认安装在 c 盘的 ~/scoop 目录下,如果你想更改安装位置:
在 powershell 中输入:
$env:SCOOP='D:\scoop'
[Environment]::SetEnvironmentVariable('USERSCOOP', $env:SCOOP, 'User')
$env:SCOOP_GLOBAL='D:\scoop'
[Environment]::SetEnvironmentVariable('SCOOP_GLOBAL', $env:SCOOP_GLOBAL, 'Machine')
接下来安装主程序,在 powershell 中执行:
Set-ExecutionPolicy RemoteSigned -Scope CurrentUser
irm get.scoop.sh | iex
安装后的 scoop 文件夹会像这样:
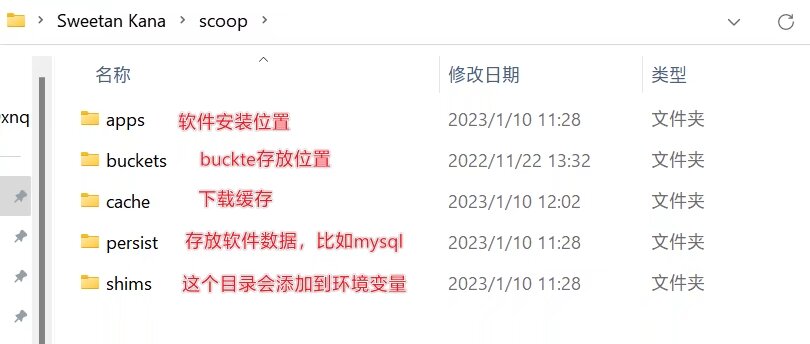
安装完成没有报错后,执行第一次 update:
scoop update
你也可以先设置代理:
scoop config proxy localhost:7891
安装 aria2,提高下载速度,安装完会自动启用:
scoop install aria2
scoop config aria2-warning-enabled false
配置
scoop 默认启用了 main bucket,如果想添加其他官方源:
scoop bucket add extras
scoop bucket add java
scoop bucket add versions
以及我使用的第三方 bucket 也推荐给大家:
scoop bucket add dorado https://github.com/chawyehsu/dorado
基本使用
更新 scoop 和 bucket
scoop update
查看安装的软件
scoop list
搜索软件
scoop search <name>
安装软件
如果软件名没有冲突,bucket 可以省略
scoop install <bucket>/<name>
批量安装用空格分割,比如:
scoop install openjdk17 python go nodejs-lts
查看软件状态
scoop status
更新软件
scoop update <name> 或 scoop update *
清除下载缓存
scoop 安装完的安装包不会自动删除,在 scoop 目录下的 cache 文件夹。
你可以手动删除也可以运行:
scoop cache rm *
清除旧版本
scoop 更新软件不会将旧版移除,只是将创建一个链接指向新版本。
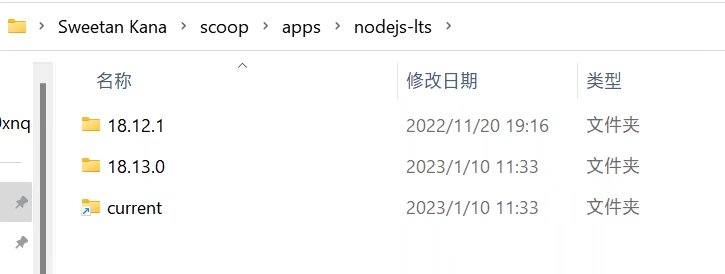
不要手动删除旧版本,使用如下命令:
scoop cleanup <name> 或 scoop cleanup *
锁定版本
锁定指定软件版本,在 scoop update * 时也不会更新。
锁定
scoop hold <name>
取消锁定
scoop unhold <name>
更多使用方法
scoop help
其他建议和说明
-
建议使用 scoop 安装纯命令行工具,如果你要安装图形化的软件,千万别安装浏览器。
-
不推荐安装 qq 微信钉钉什么的国产软件,确实是控制不了,scoop 的卸载没办法完全卸载它们。
-
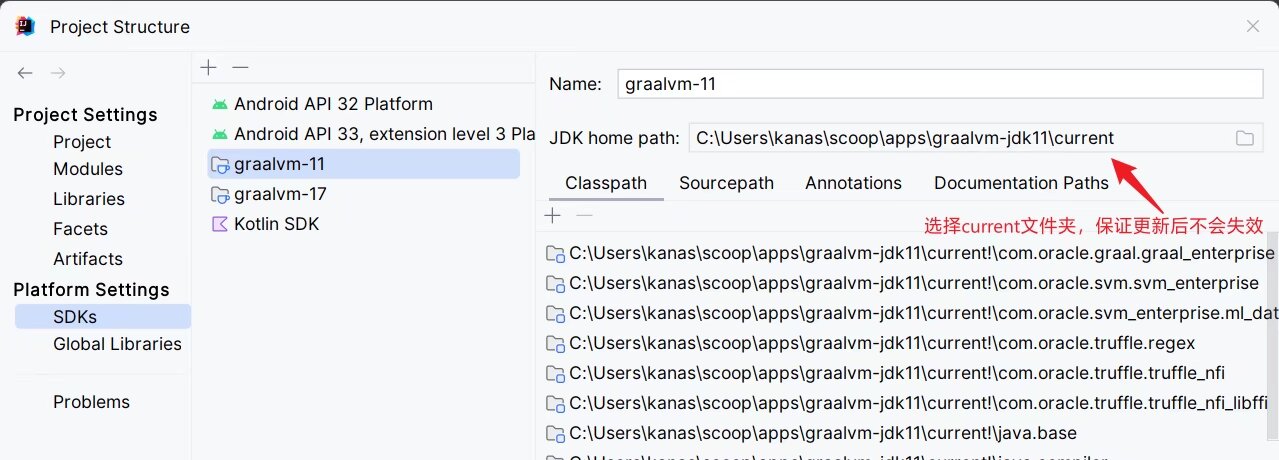
如果图形化的软件,scoop 会在开始菜单放置一个目录。
-
在使用软件过程中,请使用 current 文件夹下的程序,比如 idea 中的 jdk 配置:
JS 常见基础面试题
文章最后更新:2024-03-03

前言
花了点时间收录了一些 JavaScript 相关的概念,大部分内容只是一笔带过,详细了解相关概念请自行使用 MDN、StackOverflow、Google 查询(八股也只是作为一个目录,学习得靠自己)。
注意: 目前仅收录 JavaScript 语法及相关 API 的内容,HTML、CSS 等相关内容后续单独开设文章。
基础语法和关键字
let 和 const,var 的区别
let、const 和 var 是用于声明变量的关键字,区别如下:
作用域:
var:使用 var 声明的变量具有函数作用域或全局作用域。如果在函数内部声明的变量,那么它只在该函数内部有效。如果在函数外部声明的变量,那么它在整个代码文件中都有效。
for (var i = 0; i < 10; i++) {
// ...
}
console.log(i) // i 为 10
let 和 const:使用 let 和 const 声明的变量具有块级作用域。块级作用域是指变量只在声明的代码块(通常是花括号 {} 包裹的区域)内有效。在函数内部或其他块级作用域内使用 let 或 const 声明的变量,在代码块外部是无法访问的。
// for 就是一个块级作用域
for (let i = 0; i < 10; i++) {
// ...
}
console.log(i) // 报错 i 不存在
变量提升:
var:使用 var 声明的变量会发生变量提升。这意味着变量声明会被提升到代码的顶部,但变量的赋值仍然保留在原来的位置。因此,在变量声明之前访问变量,会返回 undefined。
console.log(a) // undefined
var a = 1
console.log(a) // 1
let 和 const:使用 let 和 const 声明的变量也会进行变量提升,但与 var 不同,let 和 const 的变量在变量声明之前是不可访问的。这种现象称为"暂时性死区"(Temporal Dead Zone,TDZ)。
console.log(a) // 报错
let a = 1
console.log(a)
重复声明:
var:使用 var 可以重复声明同一个变量,而不会报错。在重复声明后,变量会被覆盖。
var a = 1
console.log(a) // 1
var a = 2
console.log(a) // 2
let 和 const:使用 let 和 const 声明的变量在同一作用域内不允许重复声明,否则会导致语法错误。
let a = 1
console.log(a) // 1
let a = 2 // 报错,a 已经定义过
console.log(a)
变量值的修改:
var 和 let:使用这两个关键字声明的变量,其值可以修改。
const:使用 const 声明的变量是常量,其值在声明后不能再修改。
var a = 1
a = 2
let b = 1
b = 2
const c = 1
c = 2 // 报错
js 中的基础类型和对象类型
在 JavaScript 中,基础类型(Primitive Types)和对象类型(Object Types)是两种不同的数据类型。
基础类型包括以下几种:
// 数字 Number
let num1 = 123_456_789
let num2 = NaN
let num3 = Infinity
console.log(typeof num1, typeof num2, typeof num3) // number number number
// 字符串字面量 string
let str = 'hello,world'
console.log(typeof str) // string
// PS:使用构造函数创建的是字符串对象
console.log(typeof new String('hello')) // object
// 布尔值 Boolean
let b = false
console.log(typeof b) // boolean
// 空类型 Null
let n = null
console.log(typeof n) // object
// 未定义 undefined
let undef1 = undefined
let undef2 = void 0
let undef3
console.log(typeof undef1, typeof undef2, typeof undef3) // undefined undefined undefined
// 大整数 BigInt
let theBiggestInt = 9007199254740991n
let alsoHuge = BigInt(9007199254740991)
let hugeString = BigInt('9007199254740991')
let hugeHex = BigInt('0x1fffffffffffff')
let hugeBin = BigInt('0b11111111111111111111111111111111111111111111111111111')
console.log(typeof theBiggestInt) // bigint
// 符号 Symbol
let s = Symbol()
console.log(typeof s) // symbol
对象类型包括以下几种:
// 对象 Object
let obj1 = {}
let obj2 = { hello: 'hello' }
console.log(typeof obj1, typeof obj2) // object object
// 数组 Array
let arr1 = []
let arr2 = Array()
console.log(typeof arr1, typeof arr2) // object object
// PS:判断数组应该使用 Array.isArray 方法
console.log(Array.isArray(arr1)) // true
// 函数 Function
function f1() {
}
const f2 = () => {
}
console.log(typeof f1, typeof f2) // function function
主要区别如下:
- 存储方式:基础类型存储在栈内存中,而对象类型存储在堆内存中。栈内存的访问速度较快,而堆内存的访问速度较慢。
- 拷贝方式:基础类型的值在赋值时会直接拷贝,而对象类型在赋值时实际上只是复制了一个指向对象的引用,指向同一个对象。
- 比较方式:基础类型的比较是按值比较,对象类型的比较是按引用比较,即比较两个对象是否指向同一个内存地址。
typeof 与 instanceof
typeof 是一个一元运算符,用于返回一个表示操作数类型的字符串。它可以用于判断一个值的类型。
instanceof 是一个二元运算符,用于检测构造函数的原型对象是否存在于目标对象的原型链上。它用于判断一个对象是否是某个构造函数的实例,返回一个布尔值。
相同点:
- 都是用于判断值或对象的类型。
不同点:
- typeof 返回一个表示操作数类型的字符串,而 instanceof 返回一个布尔值。
- typeof 可以判断基本数据类型和函数类型,而 instanceof 用于判断对象的实例关系。
- typeof 对于数组、null 等特殊类型的判断不准确,而 instanceof 可以精确判断对象的实例关系。
例子:
console.log(typeof 'hello') // string
console.log(typeof new String('')) // object
console.log('' instanceof String) // false
console.log(new String('') instanceof String) // true
class A {
}
class B {
}
let a = new A()
let b = new B()
console.log(typeof a, typeof b) // object object
console.log(a instanceof A) // true
console.log(a instanceof B) // false
console.log(a instanceof Object) // true
模板字符串
正确的名称是模板字面量
模板字面量是用反引号(`)分隔的字面量,允许多行字符串、带嵌入表达式的字符串插值和一种叫带标签的模板的特殊结构。
基础语法:
`string text`
`string text line 1
string text line 2`
`string text ${expression} string text`
嵌套使用:
const str = `header ${
isLargeScreen() ? "" : `icon-${item.isCollapsed ? "expander" : "collapser"}`
}`
带标签的模板:
const person = "Mike";
const age = 28;
function myTag(strings, personExp, ageExp) {
const str0 = strings[0]; // "That "
const str1 = strings[1]; // " is a "
const str2 = strings[2]; // "."
const ageStr = ageExp > 99 ? "centenarian" : "youngster";
// 我们甚至可以返回使用模板字面量构建的字符串
return `${str0}${personExp}${str1}${ageStr}${str2}`;
}
const output = myTag`That ${person} is a ${age}.`;
console.log(output);
// That Mike is a youngster.
箭头函数
箭头函数是 ES6 中引入的一种新的函数表达式,是一种更简洁的语法来定义函数。
const getOne = () => 1
const printOne = () => {
console.log(1)
}
console.log(getOne()) // 1
printOne() // 1
箭头函数相较于传统的函数表达式,具有以下特点:
-
简洁:省略了 function 关键字和大括号,使得函数的定义更加简洁。
-
隐式返回:如果函数体只有一条语句,且不需要返回值,可以省略大括号和 return 关键字,函数会自动将该语句的结果作为返回值。
-
词法作用域:箭头函数不会创建自己的 this,它的 this 绑定在定义时的作用域,而不是调用时的作用域。这意味着在箭头函数内部,无法通过 this 来访问函数的调用者。
闭包
闭包是一个函数和其周围状态的组合,其中函数可以访问在创建它时存在的非局部变量。换句话说,闭包可以访问在创建它时的父函数的变量和参数,即使父函数已经返回并且执行上下文已经销毁。
function outer() {
var outerVariable = '外部作用域'
function inner() {
var innerVariable = '内部作用域'
console.log(innerVariable)
console.log(outerVariable)
}
return inner
}
var closure = outer()
closure()
闭包的主要用途:
- 封装变量:通过闭包,可以创建私有变量,避免全局命名空间的污染。闭包内部的变量对外部是不可访问的,因此可以实现封装和信息隐藏的效果。
- 保持状态:闭包可以在函数调用之间保持状态,即使函数执行结束后,闭包仍然可以保持对状态的引用。这对于一些需要记住状态的场景非常有用,例如计数器、缓存等。
- 实现函数式编程的技术:闭包可以使函数具有记忆能力,可以返回一个新的函数,该函数可以记住之前的参数和操作,从而实现柯里化(Currying)和函数组合等函数式编程的技术。
Symbol 类型
Symbol 是 JavaScript 中的一种原始数据类型。它是在 ECMAScript 6 (ES6) 标准中引入的,用于表示独一无二的标识符。每个通过 Symbol() 构造函数创建的 Symbol 值都是唯一的,不会与其他任何值相等。
Symbol 类型的特点如下:
独一无二性:每个 Symbol 值都是唯一的,无法通过简单的值比较相等。 不可变性:Symbol 值一旦创建,就不能被修改。 作为属性键:Symbol 可以作为对象的属性键,用于创建对象的私有属性或隐藏属性,以避免命名冲突。 隐藏性:使用 Symbol 作为属性键,这些属性对于常规的对象遍历和操作是不可见的。
- 创建唯一的属性键
const id: symbol = Symbol('id')
console.log(id) // 输出: Symbol(id)
const obj = {
[id]: 123,
}
console.log(obj[id]) // 输出: 123
- 防止属性名冲突
const firstName = Symbol('firstName')
const person = {
[firstName]: 'John',
lastName: 'Doe',
}
console.log(person[firstName]) // 输出: "John"
- 常见的 Symbol 方法
- Symbol.iterator:表示对象是可迭代的,可以使用 for...of 循环进行迭代。
- Symbol.asyncIterator:表示对象是可异步迭代的,可以使用 for await...of 循环进行异步迭代。
- Symbol.match:表示对象的正则匹配方法。
- Symbol.replace:表示对象的正则替换方法。
- Symbol.search:表示对象的正则搜索方法。
- Symbol.species:表示对象的构造函数。
- Symbol.hasInstance:表示对象是一个构造函数的实例。
- Symbol.toPrimitive:表示对象的默认转换方法。
for 循环和 forEach 循环的区别
for 循环是一种基本的循环结构,通过控制循环变量的起始值、结束条件和每次迭代的步长来遍历数组或其他可迭代对象。它可以使用传统的 for、while 或 do-while 语句实现。
forEach 循环是数组的原生方法之一,它提供了一种简洁的方式来遍历数组的每个元素,并执行指定的回调函数。forEach 方法接收一个回调函数作为参数,该回调函数会在数组的每个元素上执行一次。
区别:
- 语法:for 循环的语法比较复杂,需要手动控制循环变量和循环条件。而 forEach 循环是数组的原生方法,直接在数组对象上调用,语法更简洁。
- 循环控制:for 循环可以在循环体内使用 break 和 continue 语句来控制循环的终止和跳过。而 forEach 循环无法中途跳出或终止循环,它会一直遍历数组的每个元素。
例子:
const arr = [1, 2, 3, 4, 5]
for (let i = 0; i < arr.length; i++) {
console.log(arr[i])
}
arr.forEach((value, i, array) => {
// 值、索引、原数组
console.log(value, i, array)
})
JavaScript 中的作用域链(Scope Chain)
作用域链是指在 JavaScript 中变量和函数的查找机制。当访问一个变量或调用一个函数时,JavaScript 引擎会按照作用域链的顺序来查找对应的标识符。
作用域链由当前作用域和它的上层作用域组成,一直延伸到全局作用域。当一个函数嵌套在另一个函数内部时,内部函数可以访问外部函数的变量和函数,这是因为内部函数的作用域链包含了外部函数的作用域。
function outer() {
var outerVariable = 'I am outer'
function inner() {
var innerVariable = 'I am inner'
console.log(innerVariable) // 访问内部函数的变量
console.log(outerVariable) // 访问外部函数的变量
console.log(globalVariable) // 访问全局变量
}
inner()
}
var globalVariable = 'I am global'
outer()
常用方法和 API
数组的常用方法
- push:向数组末尾添加一个或多个元素,并返回数组的新长度。
- pop:删除并返回数组的最后一个元素。
- shift:删除并返回数组的第一个元素。
- unshift:向数组的开头添加一个或多个元素,并返回数组的新长度。
- concat:将多个数组合并成一个新数组,不影响原数组。
- slice:返回一个从指定位置开始到结束位置之间的新数组。
- splice:从指定位置开始删除指定数量的元素,并可选地插入新元素。
- forEach:遍历数组的每个元素,并执行回调函数。
- map:遍历数组的每个元素,并返回一个新数组,新数组的元素由回调函数的返回值组成。
- filter:遍历数组的每个元素,根据回调函数的返回值筛选出符合条件的元素,并返回一个新数组。
- reduce:将数组的每个元素累积到一个单独的值中。
- find:返回数组中满足条件的第一个元素。
- some:判断数组中是否至少存在一个元素满足条件。
- every:判断数组中的所有元素是否都满足条件。
示例:
const arr = [1, 2, 3]
const lenAfterPush = arr.push(4, 5, 6)
console.log(lenAfterPush) // 6
console.log(arr) // [1, 2, 3, 4, 5, 6]
const popNum = arr.pop()
console.log(popNum) // 6
console.log(arr) // [1, 2, 3, 4, 5]
const shiftNum = arr.shift()
console.log(shiftNum) // 1
console.log(arr) // [2, 3, 4, 5]
const lenAfterUnshift = arr.unshift(0, 1)
console.log(lenAfterUnshift) // 6
console.log(arr) // [0, 1, 2, 3, 4, 5]
const concatArr = arr.concat([6], [7, 8])
console.log(concatArr) // [0, 1, 2, 3, 4, 5, 6, 7, 8]
const sliceArr = arr.slice(2, 4)
console.log(sliceArr) // [2, 3]
arr.splice(0, 2)
console.log(arr) // [2, 3, 4, 5]
arr.forEach((value, index, array) => {
console.log(`值:${value},索引:${index},原数组:${array}`)
})
const mapArr = arr.map((n) => n * 2)
console.log(mapArr) // [4, 6, 8, 10]
const filterArr = arr.filter((n) => n % 2 === 0)
console.log(filterArr) // [2, 4]
const some = arr.some((n) => n === 3)
console.log(some) // true
const every = arr.every((n) => n > 0)
console.log(every) // true
bind、call、apply 区别
bind、call 和 apply 是 JavaScript 中用于改变函数执行上下文的方法。
- bind:bind 方法会创建一个新函数,并将新函数的执行上下文绑定到指定的对象。该方法返回一个绑定后的函数,但并不立即执行。
- call:call 方法会立即执行函数,并将函数的执行上下文绑定到指定的对象。除了第一个参数是绑定的对象外,后续的参数是函数调用时的参数。
- apply:apply 方法与 call 类似,但接受的参数是以数组或类数组形式传递的。
示例:
function logThis(arg) {
console.log(this, arg)
}
logThis('直接调用') // globalThis '直接调用'
const obj = { name: 'obj' }
logThis.bind(obj)('bind 调用') // { name: 'obj' } 'bind 调用'
logThis.call(obj, 'call 调用') // { name: 'obj' } 'call 调用'
logThis.apply(obj, ['apply 调用']) // { name: 'obj' } 'apply 调用'
Promise.all、Promise.race、Promise.allSettled
Promise.all 接收一个 Promise 数组作为参数,返回一个新的 Promise 对象。它会等待所有的 Promise 都被解决(resolved)或有一个 Promise 被拒绝(rejected)。只有当所有 Promise 都解决时,Promise.all 才会返回一个解决值组成的数组;如果任何一个 Promise 被拒绝,它会立即拒绝并返回被拒绝的原因。
const taskList = [
Promise.resolve('成功'),
Promise.resolve('成功'),
Promise.reject('失败'),
]
const result = await Promise.all(taskList)
console.log(result) // 失败
Promise.race 也接收一个 Promise 数组作为参数,返回一个新的 Promise 对象。它会等待第一个解决或拒绝的 Promise,并将其解决值或拒绝原因作为结果。无论第一个 Promise 是解决还是拒绝,Promise.race 都会返回相应的结果。
const taskList = [
new Promise((resolve) => setTimeout(() => resolve('成功1'), 500)),
new Promise((resolve) => setTimeout(() => resolve('成功2'), 1000)),
new Promise((_, reject) => setTimeout(() => reject('失败'), 600)),
]
const result = await Promise.race(taskList)
console.log(result) // 成功1
Promise.allSettled 接收一个 Promise 数组作为参数,并返回一个新的 Promise。无论 Promise 是 resolved 还是 rejected,新的 Promise 都会变为 resolved 状态,返回值是一个包含每个 Promise 结果的对象数组,每个对象包含 status 和 value 属性,表示 Promise 的状态和结果。
const taskList = [
new Promise((resolve) => setTimeout(() => resolve('成功1'), 500)),
new Promise((resolve) => setTimeout(() => resolve('成功2'), 1000)),
new Promise((_, reject) => setTimeout(() => reject('失败'), 600)),
]
const result = await Promise.allSettled(taskList)
console.log(result) // 成功1,成功2,失败
Web Workers
Web Workers 是 HTML5 标准中提供的一项技术,它允许在浏览器中创建多个后台线程,独立于主线程运行。Web Workers 的作用是在后台执行一些耗时的操作,以避免阻塞主线程,提高前端应用的性能和响应性。
Web Workers 的使用场景包括:
执行复杂的计算:将复杂的计算任务交给 Web Workers,在后台线程中执行,避免阻塞主线程,确保页面的流畅性。
大规模数据处理:处理大量数据时,可以将数据分块传递给 Web Workers,进行并行处理,提高处理速度。
执行网络请求:Web Workers 可以独立处理网络请求,例如发送 AJAX 请求或进行 WebSocket 通信,以避免主线程被阻塞。
主线程和 Web Workers 之间的通信方式主要有两种:
通过消息传递:主线程和 Web Workers 之间可以通过 postMessage()方法发送消息,并通过 onmessage 事件接收消息。这种方式可以实现双向通信,在消息中传递数据和指令。
// 创建Web Worker
const worker = new Worker('worker.js');
// 发送消息给Web Worker
worker.postMessage({ message: 'Hello from main thread!' });
Web
Workers接收消息的示例代码:
// 监听消息事件
self.addEventListener('message', (event) => {
const message = event.data;
console.log('Received message from main thread:', message);
});
通过共享内存:主线程和 Web Workers 可以通过 SharedArrayBuffer 或 Transferable Objects 共享内存。这种方式主要用于大规模数据的传递和共享,可以提高性能。
// 主线程创建共享内存
const sharedBuffer = new SharedArrayBuffer(1024)
// 将共享内存传递给Web Worker
const worker = new Worker('worker.js')
worker.postMessage(sharedBuffer)
// Web Worker中访问共享内存
self.addEventListener('message', (event) => {
const sharedBuffer = event.data
// 使用共享内存进行数据处理
})
注意:由于 Web Workers 运行在独立的线程中,它们无法直接访问 DOM 和一些浏览器 API。如果需要在 Web Workers 中操作 DOM 或使用特定的浏览器 API,可以通过消息传递与主线程进行通信,由主线程代为执行相关操作。
相关概念
同步和异步
在编程中,同步和异步是两种不同的执行方式。同步是指代码按照顺序一行一行地执行,当前代码块执行完毕后才执行下一个代码块,而异步则是指代码不按照顺序执行,而是将任务放入队列中,继续执行后面的代码,等到任务完成后再去处理它。
在前端开发中,异步编程经常用于处理网络请求、事件处理等需要耗时的操作,以避免阻塞主线程。常见的异步编程方式包括回调函数、Promise、async/await 等。
JS 中的事件循环(Event Loop)
事件循环是 JavaScript 中用于处理异步操作的机制。JavaScript 是单线程的,意味着一次只能执行一个任务。然而,JavaScript 可以通过事件循环来处理异步操作,使得程序能够在等待某些操作完成的同时继续执行其他任务。
事件循环包含了以下几个主要的组成部分:
- 主线程(调用栈):负责执行同步任务。
- 任务队列(任务队列):用于存储异步任务的队列。
- s 事件循环(Event Loop):负责将异步任务从任务队列中取出,并将其添加到调用栈中执行。
console.log('Start')
setTimeout(function () {
console.log('Timeout callback')
}, 0)
Promise.resolve().then(function () {
console.log('Promise callback')
})
console.log('End')
在上述代码中,setTimeout 和 Promise 分别代表了一种异步操作。通过事件循环机制,即使 setTimeout 的延迟时间为 0,它仍然会被放置在任务队列中,并在调用栈为空时执行。而 Promise 的回调函数则会在调用栈为空时,被放置在微任务队列中。因此,上述代码的输出顺序为:
Start
End
Promise callback
Timeout callback
这是因为同步任务会立即执行,所以先输出 "Start" 和 "End"。然后,微任务队列中的回调函数会在调用栈为空时执行,所以输出 "Promise callback"。最后,任务队列中的定时器回调函数会被放置到调用栈中执行,输出 "Timeout callback"。
防抖(Debounce)和节流(Throttle)
防抖(Debounce)和节流(Throttle)都是用于限制事件触发频率的技术。
防抖指的是在事件触发后等待一段时间(比如 300 毫秒),如果这段时间内没有再次触发该事件,那么执行相应的操作;如果在等待时间内又触发了该事件,则重新计时,等待一段时间后再执行。防抖常用于处理频繁触发的事件,例如搜索框输入事件。
节流指的是在一段时间内只执行一次事件,无论该事件触发多频繁。比如设置一个 300 毫秒的时间间隔,在该时间内只执行一次事件操作,无论触发多少次事件。节流常用于限制某些操作的执行频率,例如滚动事件。
function throttle(func, delay) {
let timerId
return function (...args) {
if (timerId) {
return // 在延迟期间内已经触发过一次,则忽略后续触发
}
timerId = setTimeout(() => {
func.apply(this, args) // 执行函数
timerId = null // 重置定时器标识
}, delay)
}
}
// 使用示例
function handleScroll() {
console.log('Scroll event handler')
}
const throttledScroll = throttle(handleScroll, 300)
window.addEventListener('scroll', throttledScroll)
在上面的示例中,throttle 函数接受一个函数 func 和一个延迟时间 delay 作为参数。返回的函数是一个节流函数,它会在延迟时间内只执行一次传入的函数 func。
在使用示例中,我们定义了一个名为 handleScroll 的滚动事件处理函数,并通过 throttle 函数创建了一个节流函数 throttledScroll。将 throttledScroll 作为事件监听器绑定到 scroll 事件上,这样在滚动事件触发时,handleScroll 函数就会被节流地执行,限制了触发频率。
function throttle(func, delay) {
let lastCallTime = 0
return function (...args) {
const currentTime = Date.now()
if (currentTime - lastCallTime >= delay) {
func.apply(this, args)
lastCallTime = currentTime
}
}
}
// 使用示例
function handleResize() {
console.log('Resize event handler')
}
const throttledResize = throttle(handleResize, 500)
window.addEventListener('resize', throttledResize)
在上述示例中,throttle 函数接受一个函数 func 和一个延迟时间 delay 作为参数。返回的函数是一个节流函数,它会在延迟时间内只执行一次传入的函数 func。
在使用示例中,我们定义了一个名为 handleResize 的调整窗口大小事件处理函数,并通过 throttle 函数创建了一个节流函数 throttledResize。将 throttledResize 作为事件监听器绑定到 resize 事件上,这样在窗口调整大小事件触发时,handleResize 函数就会被节流地执行,限制了触发频率。
深拷贝(Deep Copy)和浅拷贝(Shallow Copy)
- 浅拷贝是创建一个新对象或数组,并复制原始对象或数组中的引用,而不是复制引用指向的对象或数组本身。因此,如果原始对象或数组中的引用对象发生变化,浅拷贝的对象或数组也会受到影响。
手写深拷贝:
function deepClone(obj: any): any {
if (obj === null || typeof obj !== 'object') {
return obj // 非对象或 null 直接返回
}
let clone: any
if (Array.isArray(obj)) {
clone = []
for (let i = 0; i < obj.length; i++) {
clone[i] = deepClone(obj[i]) // 递归复制数组元素
}
} else {
clone = {}
for (const key in obj) {
if (Object.prototype.hasOwnProperty.call(obj, key)) {
clone[key] = deepClone(obj[key]) // 递归复制对象属性
}
}
}
return clone
}
- 深拷贝是创建一个全新的对象或数组,并递归地复制原始对象或数组中的所有值和引用对象。这意味着如果原始对象或数组中的引用对象发生变化,深拷贝的对象或数组不会受到影响。
JS 模块化
模块化是一种将程序分割为独立模块的开发方式,它能够提高代码的可维护性、可复用性和可测试性。在前端开发中,常见的模块化规范有 CommonJS 和 ES6 模块化。
CommonJS 是一种用于服务器端 JavaScript 的模块化规范,它使用 require 和 module.exports 来导入和导出模块。CommonJS 模块化是同步的,模块的导入是在运行时进行的。
ES6 模块化是 ECMAScript 6 标准引入的一种模块化规范,它使用 import 和 export 来导入和导出模块。ES6 模块化是静态的,模块的导入在编译时进行。
函数式编程
函数式编程(Functional Programming)是一种编程范式,它将计算过程看作是函数之间的转换和组合,强调函数的纯粹性和不可变性。函数式编程中的函数被视为第一等公民,可以作为参数传递、返回值,以及组合成更高阶的函数。
函数式编程的基本概念包括:
- 纯函数(Pure Function):输入相同,输出始终相同,并且没有副作用的函数。
- 不可变性(Immutability):数据一旦创建就不可更改,对数据的修改实际上是创建了新的数据。
- 高阶函数(Higher-Order Function):接受一个或多个函数作为参数,或者返回一个新函数的函数。
- 声明式编程(Declarative Programming):通过表达式描述目标结果,而不是指定详细的执行步骤。
函数式编程与命令式编程的区别在于,命令式编程更加关注实现的步骤和控制流程,而函数式编程更加关注数据的转换和变换。函数式编程的优势包括代码的可读性和可维护性更强,易于测试和调试,以及能够更好地处理并发和异步编程。
高阶函数
高阶函数是指接收一个或多个函数作为参数,并/或者返回一个函数的函数。它们常用于函数式编程中,用于处理函数的组合、封装和抽象。
一些常见的高阶函数包括:map、filter、reduce、sort 等。
// 使用 map 高阶函数
const numbers = [1, 2, 3, 4, 5]
const doubledNumbers = numbers.map((num) => num * 2)
console.log(doubledNumbers) // [2, 4, 6, 8, 10]
// 使用 filter 高阶函数
const evenNumbers = numbers.filter((num) => num % 2 === 0)
console.log(evenNumbers) // [2, 4]
// 使用 reduce 高阶函数
const sum = numbers.reduce((accumulator, currentValue) => accumulator + currentValue, 0)
console.log(sum) // 15
// 使用 sort 高阶函数
const sortedNumbers = numbers.sort((a, b) => a - b)
console.log(sortedNumbers) // [1, 2, 3, 4, 5]
函数柯里化
函数柯里化(Currying)是一种将接受多个参数的函数转化为接受一个参数的函数序列的过程。通过函数柯里化,我们可以将原来接受多个参数的函数转化为一系列只接受一个参数的函数,每个函数返回一个新的函数,最终返回结果。函数柯里化的作用是可以部分应用函数,以创建更灵活的函数。
柯里化的优势包括:
- 参数复用:通过柯里化,我们可以固定部分参数,生成一个新的函数,方便在不同场景下复用这些固定的参数。
- 延迟执行:柯里化可以延迟函数的执行,通过返回新的函数,可以在需要的时候再执行。
// 柯里化函数
function curry(fn) {
return function curried(...args) {
if (args.length >= fn.length) {
return fn(...args)
} else {
return function (...nextArgs) {
return curried(...args, ...nextArgs)
}
}
}
}
// 原始函数
function add(a, b, c) {
return a + b + c
}
// 柯里化后的函数
const curriedAdd = curry(add)
console.log(curriedAdd(1)(2)(3)) // 输出 6
console.log(curriedAdd(1, 2)(3)) // 输出 6
console.log(curriedAdd(1)(2, 3)) // 输出 6
JS 经典之眼见不一定为实
文章最后更新:2023-11-21

当 a 是什么的时候,下面的判断成立?
const a = ?
if (a == 1 && a == 2 && a == 3) {
console.log('true')
}
重写对象的 valueOf 方法
const a = {
i: 1,
valueOf() {
return this.i++
},
}
在 JavaScript 中,当一个对象和数字进行比较时,会发生类型转换,JavaScript 会尝试将对象转换为原始值。
首先,JavaScript 会调用对象的 valueOf 方法。如果该方法返回的是原始值,比较就会基于这个原始值进行。如果 valueOf
方法没有返回原始值(或者不是一个原始值),JavaScript 会继续调用对象的 toString 方法。最终,如果 toString
方法返回了原始值,比较将基于这个原始值进行。
如果 valueOf 和 toString 方法均未返回原始值,JavaScript 将抛出一个类型错误。
MDN: JavaScript 调用
valueOf方法来将对象转换成基本类型值。
重写对象的 toString 方法
const a = {
i: 1,
toString() {
return this.i++
},
}
原理和上面的类似
替换数组的方法
const a = [1, 2, 3]
a.join = c.shift
数组和数字比较,根据上面的逻辑,会先调用 valueOf 再调用数组的 toString 方法转换为原始值,而数组默认的 toString 会调用
join 方法,我们可以重写其中任意一个方法。
替换为 shift 后,每次比较就会从数组头部取出一个元素。
Reflect.defineProperty
globalThis._value = 1
Reflect.defineProperty(globalThis, 'a', {
get() {
return _value++
},
})
相信看过 Vue2 的响应式原理的应该对 defineProperty 不陌生,这里给全局 this 添加了一个 get() 方法,思路和第一二种是一致的
MDN - Object.defineProperty 介绍 MDN: 静态方法
Reflect.defineProperty()基本等同于Object.defineProperty()方法,唯一不同是返回 Boolean 值。
Proxy 代理
const a = new Proxy(
{ i: 1 },
{
get(target, p, receiver) {
if (p === Symbol.toPrimitive) return () => target.i++
},
},
)
Vue3 的响应式就是基于 Proxy 的,思路和上面是一致的
多线程摸奖
// main.js
const share = new SharedArrayBuffer(1)
new Worker('./competitors.js').postMessage(share)
new Worker('./competitors.js').postMessage(share)
new Worker('./competitors.js').postMessage(share)
new Worker('./worker.js').postMessage(share)
// competitors.js
onmessage = ({ data }) => {
const shareArr = new Uint8Array(data)
setInterval(() => (shareArr[0] = Math.floor(Math.random() * 3) + 1))
}
// worker.js
onmessage = ({ data }) => {
const shareArr = new Uint8Array(data)
Reflect.defineProperty(self, 'a', {
get() {
return shareArr[0]
},
})
let count = 0
while (!(a === 1 && a === 2 && a === 3)) count++
console.log(`跑了${count}次,a === 1 && a === 2 && a === 3 成立啦`)
}
利用 SharedArrayBuffer 来在多个 worker 之间共享内存,其中三个随机设置 1-3 的值,另一个获取值并比较
浏览器对 SharedArrayBuffer 的限制比较严格,必须是安全上下文并开启跨域隔离才可以使用
if (window.isSecureContext && window.crossOriginIsolated) {
// 页面在安全上下文中并开启跨域隔离
} else {
// ...
}
这个是最邪门的一个方式,至少在我电脑上跑了 41490778 次
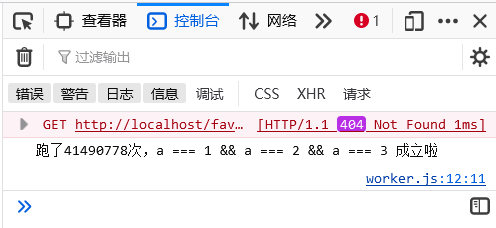
CVE-2023-34092
文章最后更新:2024-01-20

前几天突然收到 Github 发好几个邮件,基本都是提醒 Vite 有漏洞提醒更新版本,打算来复现一下这个 CVE-2023-34092。
复现用的代码已上传至 Github:https://github.com/blyrin/test-cve-2023-34092
说明
在不区分大小写的文件系统上(Windows),可绕过 vite.config.js 中 server.fs.deny 配置的被禁止访问的文件。
影响范围
= 5.0.0,<= 5.0.11
补丁
已在 5.0.12、4.5.2、3.2.8、2.9.17 中修复。
复现过程
环境配置
- 使用
npm create vite创建标准的 vite 项目。 - 指定 vite 版本
npm install vite@5.0.11。 - 创建
.env文件,添加内容。 - 在
vite.config.js中配置server: { fs: { deny: ['.env'] } }。 npm run dev启动。
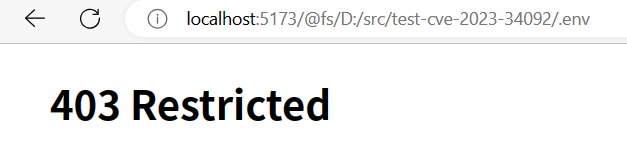
验证
- 使用浏览器或 curl 命令访问
http://localhost:5173/@fs/<项目路径>/.env,无法访问。
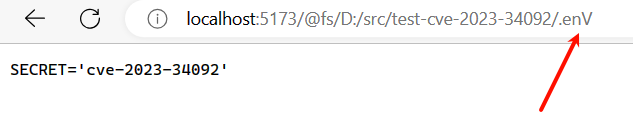
- 将其中的部分字符改为大写
http://localhost:5173/@fs/<项目路径>/.enV,成功获取。
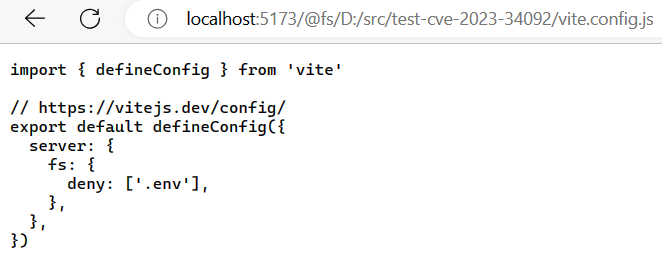
- 甚至可直接查看
http://localhost:5173/@fs/<项目路径>/vite.config.js来获取被禁用的文件列表。
SpringBoot 3.2 尝鲜
文章最后更新:2023-11-25
SpringBoot 已在 2023-11-23 正式发布,此版本支持了大量有用的新特性:
- 支持虚拟线程
- 对 JVM Checkpoint Restore (Project CRaC) 的初始支持
- SSL Bundle 重载
- 大量可观测性改进
- RestClient 的支持
- JdbcClient 的支持
- 支持 Jetty 12
- 支持 Spring for Apache Pulsar
- 对 Kafka 和 RabbitMQ 的 SSL 捆绑包支持
- 重新设计了嵌套 Jar 处理
- Docker 映像构建改进
相比 3.1 的变化
-
日志输出包括应用程序名称 如果配置了
spring.application.name,默认日志输出将包括应用程序名称,可以将logging.include-application-name设置为 false 来关闭。 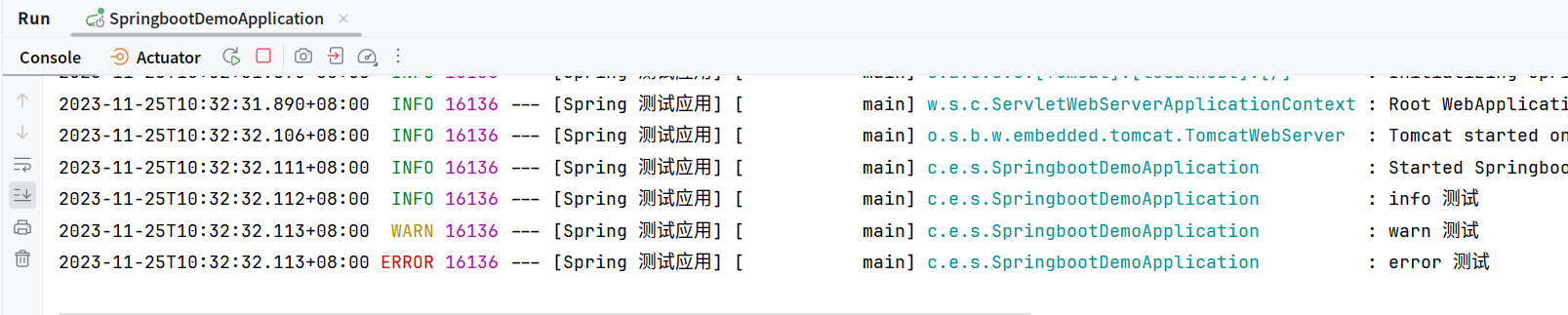
-
自动配置的 UserDetailsService 如果依赖中包含一个或多个
spring-security-oauth2-client、spring-security-oauth2-resource-server、spring-security-saml2-service-provider,将关闭InMemoryUserDetailsManager的自动配置 bean(在Reactive应用中为MapReactiveUserDetailsService)。如果在使用上述依赖项之一,并且要使用
InMemoryUserDetailsManager或MapReactiveUserDetailsService,需要手动配置所需的 Bean。 -
OTLP Endpoint 默认的
management.otlp.tracing.endpoint已被删除。 可设置management.otlp.tracing.endpoint为http://localhost:4318/v1/traces来恢复。 -
Jetty 12 Spring Boot 现在支持
Jetty 12。Jetty 12支持Servlet 6.0 API。 -
Kotlin 1.9.0
-
嵌套 Jar 因为不再支持 Java 8,加载 Spring Boot 的
Uber Jar底层代码已被重写。 以前的 URL 格式jar:file:/dir/myjar.jar:BOOT-INF/lib/nested.jar!/com/example/MyClass.class已替换为jar:nested:/dir/myjar.jar/!BOOT-INF/lib/nested.jar!/com/example/MyClass.class。 更新后的代码还使用了java.lang.ref.Cleaner(JDK 9 的一部分)用于资源管理。
以上内容翻译自Spring-Boot-3.2-Release-note
新特性尝鲜
虚拟线程
开启虚拟线程
虚拟线程的使用也非常简单,只需要在配置文件中开启,Spring Boot 会安排好一切,前提是 JDK 版本要大于等于 21。
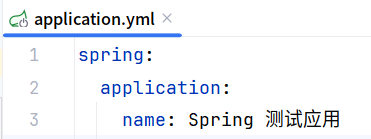
spring:
application:
name: Spring 测试应用
threads:
virtual:
# 开启虚拟线程支持
enabled: true
开启后,Tomcat 等 Servlet 容器将自动使用虚拟线程。
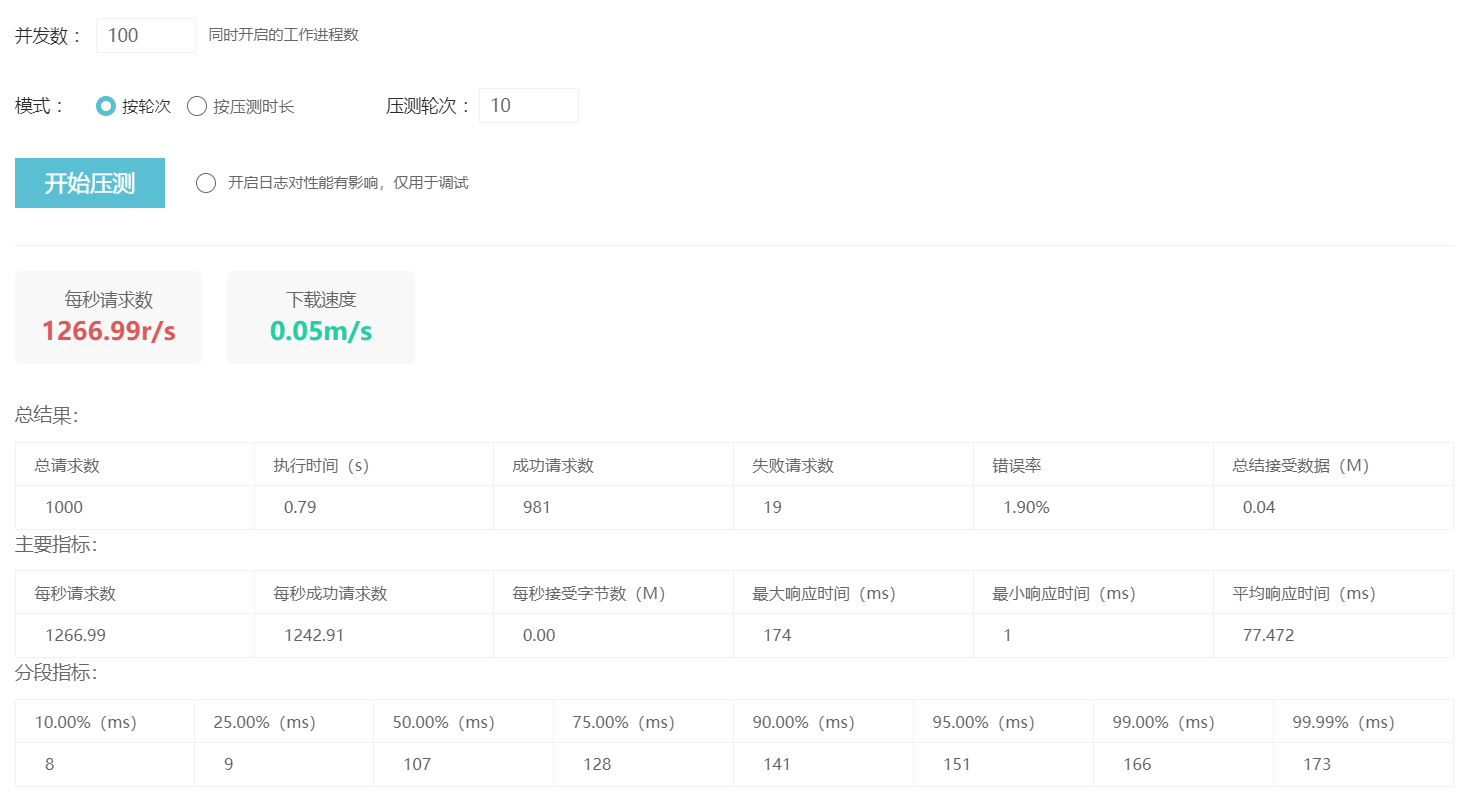
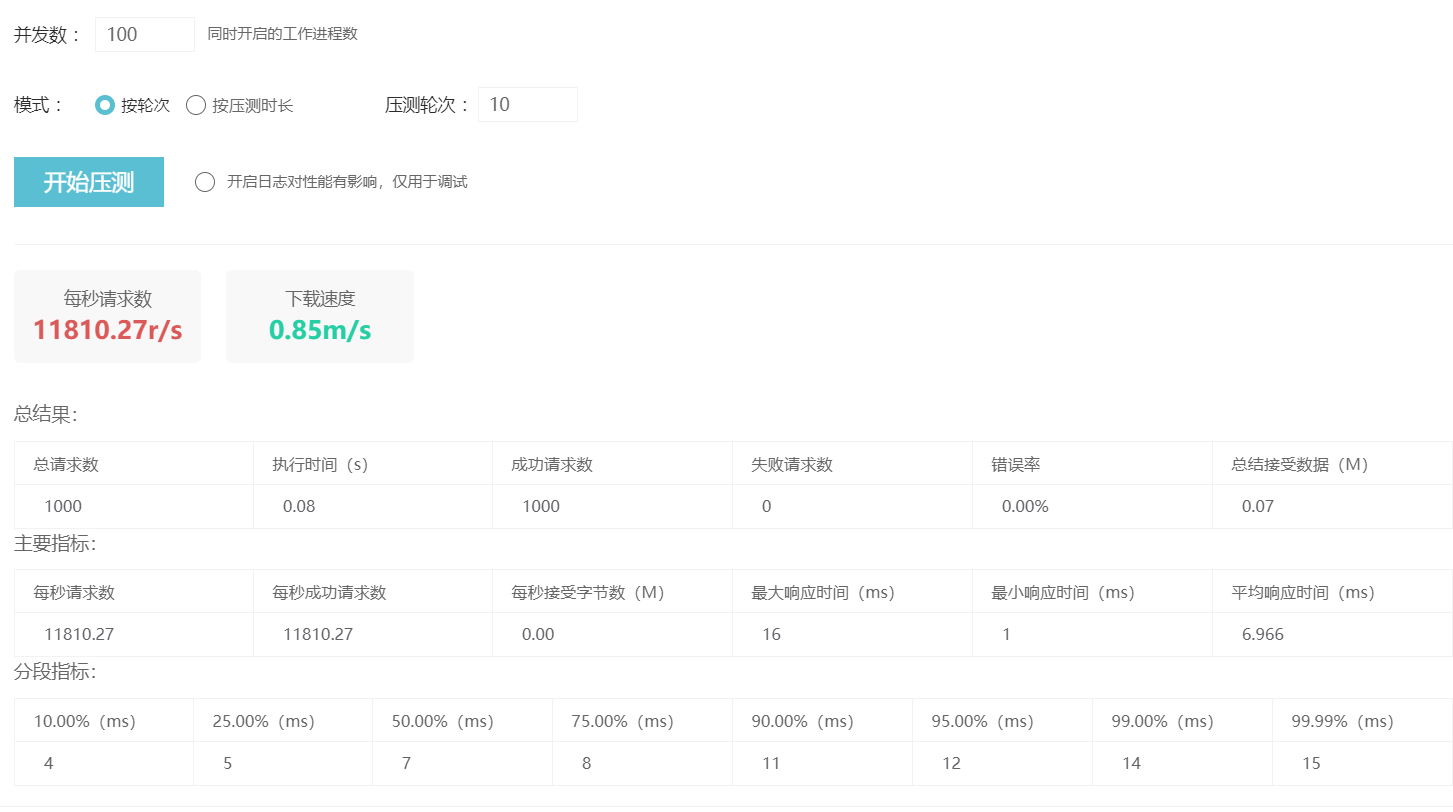
吞吐量测试
编写一个接口并来一次不严谨的测试。
@GetMapping("/test")
public ResponseEntity<String> test() {
var threadName = Thread.currentThread().toString();
log.info("线程名称: {}", threadName);
return ResponseEntity.ok(threadName);
}
不启用虚拟线程:


启用虚拟线程:

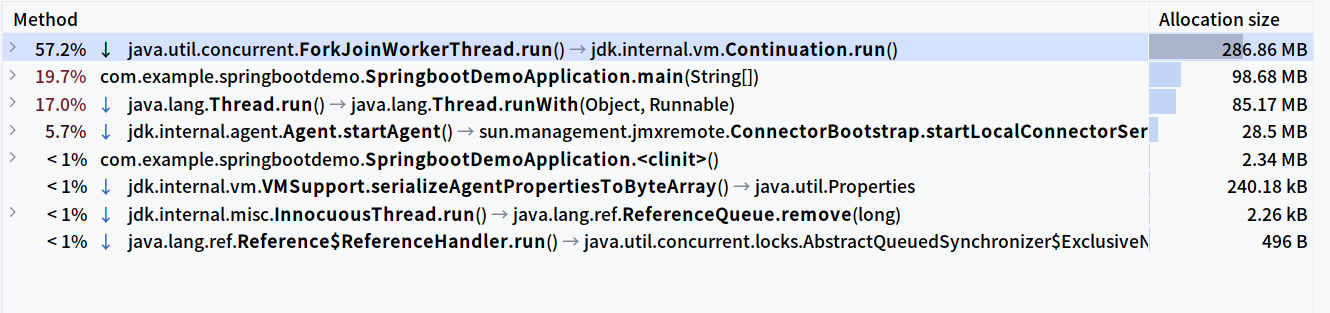
ThreadLocal 支持
比起性能,我更关心的是 ThreadLocal 能不能用 🧐,毕竟 ThreadLocal 是在单个操作系统线程中共享,多个虚拟线程很可能是同一个线程在执行。
写一个接口和过滤器来测试,这里直接用了 slf4j 的 MDC 了,Spring Boot 默认的 logback 就是用 ThreaedLocal 实现的。
@Component
public class TraceIdFilter implements Filter {
private final static Logger log = LoggerFactory.getLogger(SpringbootDemoApplication.class);
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
var traceId = RandomStringUtils.randomAlphabetic(8);
log.info("filter traceId: {}", traceId);
MDC.put("mdc-trace-id", traceId);
chain.doFilter(request, response);
}
}
@GetMapping("/thread-local")
public ResponseEntity<String> threadLocal() {
var traceId = MDC.get("mdc-trace-id");
log.info("controller traceId: {}", traceId);
return ResponseEntity.ok(traceId);
}
跑一下看看。

应该是没问题的 😆。
RestClient
Spring 5 的时候,出了一个 WebClient 用于对 RestTemplate 的响应式包装,但 WebClient 需要响应式 web 才能用,所以 Spring
6.1 出了一个 RestClient,在非响应式 web 也能用,并且这个 RestClient 不使用 Servlet 线程,不会占用 Servlet 线程资源。
RestClient
的具体使用可以参考官方文档
,这里给出一个简单的例子。
@GetMapping("/rest-client")
public ResponseEntity<Object> restClient() {
var restClient = RestClient.create();
return restClient.get()
.uri("https://api.github.com/users/{username}/repos", "blyrin")
.accept(MediaType.APPLICATION_JSON)
.acceptCharset(StandardCharsets.UTF_8)
.retrieve()
.toEntity(Object.class);
}
JdbcClient
JdbcClient 是对 JdbcTemplate 的封装,更加简单方便,需要 spring-boot-starter-jdbc 依赖。
下面是一个增删改查的例子。
public record Person(Integer id, String name, Instant createdAt) {
}
@Repository
public class PersonRepository {
private final JdbcClient jdbcClient;
public PersonRepository(JdbcClient jdbcClient) {
this.jdbcClient = jdbcClient;
}
public List<Person> findAll() {
return jdbcClient
.sql("select id, name, created_at from person")
// 使用默认的 SimplePropertyRowMapper 进行映射,自动驼峰转换
.query(Person.class)
.list();
}
public Optional<Person> findById(Integer id) {
return jdbcClient
.sql("select id, name, created_at from person where id = :id")
.param("id", id)
.query(Person.class)
.optional();
}
@Transactional
public Integer save(Person person) {
var keyHolder = new GeneratedKeyHolder();
jdbcClient.sql("insert into person(id, name, created_at) values(:id, :name, :created_at) returning id")
.param("id", person.id())
.param("name", person.name())
.param("created_at", person.createdAt())
.update(keyHolder);
return keyHolder.getKeyAs(Integer.class);
}
@Transactional
public void update(Person person) {
jdbcClient.sql("update person set name = :name, created_at = :created_at where id = :id)")
.param("name", person.name())
.param("created_at", person.createdAt())
.param("id", person.id())
.update();
}
@Transactional
public void delete(Integer id) {
jdbcClient.sql("update from person where id = :id)")
.param("id", id)
.update();
}
}
@RestController
@RequestMapping("/person")
public class PersonController {
private final PersonRepository personRepository;
public PersonController(PersonRepository personRepository) {
this.personRepository = personRepository;
}
@GetMapping
public ResponseEntity<List<Person>> getPersons() {
return ResponseEntity.ok(personRepository.findAll());
}
@GetMapping("/{id}")
public ResponseEntity<Person> getPersonById(@PathVariable Integer id) {
return ResponseEntity.of(personRepository.findById(id));
}
@PostMapping
public ResponseEntity<Integer> addPerson(@RequestBody Person person) {
return ResponseEntity.ok(personRepository.save(person));
}
@PutMapping
public ResponseEntity<?> modifyPerson(@RequestBody Person person) {
personRepository.update(person);
return ResponseEntity.ok().build();
}
@DeleteMapping("/{id}")
public ResponseEntity<?> deletePersonById(@PathVariable Integer id) {
personRepository.delete(id);
return ResponseEntity.ok().build();
}
}
栢码项目面经
文章最后更新:2024-03-27

收集了栢码群里面用栢码项目相关的面经。
介绍一下 Jwt,为什么用 jwt,对比 session 方案的好处和坏处
jwt 的优点:
- 可扩展性好。应用程序分布式部署的情况下,session 需要做多机数据共享,通常可以存在数据库或者 redis 里面。而 jwt 不需要。
- 无状态。jwt 不在服务端存储任何状态。jwt 的载荷中可以存储一些常用信息,用于交换信息,有效地使用 JWT,可以降低服务器查询数据库的次数。
jwt 的缺点:
-
安全性。由于 jwt 的 payload 是使用 base64 编码的,并没有加密,因此 jwt 中不能存储敏感数据。而 session 的信息是存在服务端的,相对来说更安全。
-
性能。由于是无状态使用 JWT,所有的数据都被放到 JWT 里,如果还要进行一些数据交换,那载荷会更大,经过编码之后导致 jwt 非常长,cookie 的限制大小一般是 4k,cookie 很可能放不下,所以 jwt 一般放在 local storage 里面。并且用户在系统中的每一次 http 请求都会把 jwt 携带在 Header 里面,http 请求的 Header 可能比 Body 还要大。而 sessionId 只是很短的一个字符串,因此使用 jwt 的 http 请求比使用 session 的开销大得多。
-
一次性。无状态是 jwt 的特点,但也导致了这个问题,jwt 是一次性的。想修改里面的内容,就必须签发一个新的 jwt。
-
无法废弃。一旦签发一个 jwt,在到期之前就会始终有效,无法中途废弃。例如你在 payload 中存储了一些信息,当信息需要更新时,则重新签发一个 jwt,但是由于旧的 jwt 还没过期,拿着这个旧的 jwt 依旧可以登录,那登录后服务端从 jwt 中拿到的信息就是过时的。为了解决这个问题,我们就需要在服务端部署额外的逻辑,例如设置一个黑名单,一旦签发了新的 jwt,那么旧的就加入黑名单(比如存到 redis 里面),避免被再次使用。
-
续签。传统的 cookie 续签方案一般都是框架自带的,session 有效期 30 分钟,30 分钟内如果有访问,有效期被刷新至 30 分钟。一样的道理,要改变 jwt 的有效时间,就要签发新的 jwt。最简单的一种方式是每次请求刷新 jwt,即每个 http 请求都返回一个新的 jwt。这个方法不仅暴力不优雅,而且每次请求都要做 jwt 的加密解密,会带来性能问题。另一种方法是在 redis 中单独为每个 jwt 设置过期时间,每次访问时刷新 jwt 的过期时间。
你的项目用了 spring boot 3,相对 2 有什么不同 (提到了 swagger 不适配?)
spring boot 3 和 spring boot 2 的部分区别:
-
最低环境。SpringBoot2 的最低版本要求为 Java8,支持 Java9;而 SpringBoot3 决定使用 Java17 作为最低版本,并支持 Java19。Spring Boot2 基于 Spring Framework5 开发;而 SpringBoot3 构建基于 Spring Framework6 之上,需要使用 Spring Framework6。
-
GraalVM 支持。相比 SpringBoot2,SpringBoot3 的 Spring Native 也是升级的一个重大特性,支持使用 GraalVM 将 Spring 的应用程序编译成本地可执行的镜像文件,可以显著提升启动速度、峰值性能以及减少内存使用。
GraalVm 配置参考:https://www.itbaima.cn/space/project/deploy/8
-
图片 Banner。在 SpringBoot2 中,自定义 Banner 支持图片类型;而现在 Spring Boot3 自定义 Banner 只支持文本类型(banner.txt),不再支持图片类型。
-
依赖项。删除了对一些附加依赖项的支持,包括 Apache ActiveMQ、Atomikos、EhCache2 和 HazelCast3。
-
Java EE 已经变更为 Jakarta EE(javax.servlet.Filter 要改为 jakarta.servlet.Filter)。
swagger 问题:
- 使用 springdoc (https://springdoc.org/)。
- 使用 springfox (http://springfox.io/)
Spring security 你是如何配置的,filter 是怎么编写的
新版 security 配置全面采用了 lambda 表达式来配置,例子:
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
http.csrf(AbstractHttpConfigurer::disable);
http.formLogin(formLogin -> formLogin
.loginProcessingUrl("/auth/login")
.successHandler((request, response, authentication) -> {
})
.failureHandler((request, response, authentication) -> {
}));
http.logout(logout -> logout
.logoutUrl("/auth/logout")
.logoutSuccessHandler((request, response, authentication) -> {
}));
http.authorizeHttpRequests(request -> request
.requestMatchers("/auth/**")
.permitAll()
.anyRequest()
.authenticated()
);
return http.build();
}
为什么用 RabbitMQ 而不创建多个线程
任何 MQ 相关的问题,优先想到“异步”、“解耦”。
- 提高系统稳定性,系统 down 了,消息是在外部的不会丢失。
- 线程会占用资源,消息队列就可以把发短信的操作放到其他机器。
- 架构思想,应用服务尽量只做逻辑,数据放外部。
为什么要编写工具转换 DTO 和 VO,相比 BeanUtils.copyProperties 有优势吗,运用反射是不是效率比较低
(表达意思:我会玩反射)
BeanUtils.copyProperties 底层也是反射,但 spring 做了大量逻辑优化和缓存优化,性能不会很低。
介绍一下限流工具类的功能,redis 的键值分别是什么,redis 中用什么数据结构储存黑名单,假如有几十万个 ip 请求,都要记录在 redis 吗,是不是太消耗资源
限流工具类的功能:限流(难道还有其他功能?)
限流工具类 的 redis 的键值分别是什么:key 是 ip 地址,value 是访问次数
ip 黑名单存储结构:字符串(简单高效!)
几十万个 ip 请求:这个量 redis 完全存的下,如果占用太高可以考虑转为无符号整型
Redis 集群有搭建过吗
Minio 如何实现文件的存取
Minio 的主要特点:
-
简单易用:Minio 的安装和配置非常简单,只需要下载并运行相应的二进制文件即可。它提供- 了一个 Web UI,可以通过界面管理存储桶和对象。
-
可扩展性:Minio 可以轻松地扩展到多个节点,以提供高可用性和容错能力。它支持多种部署- 模式,包括单节点、主从复制和集群等。
-
高可用性:Minio 提供了多种机制来保证数据的可靠性和可用性,包括冗余备份、数据复制和- 故障转移等。
-
安全性:Minio 提供了多种安全机制来保护数据的机密性和完整性,包括 SSL/TLS 加密、- 访问控制和数据加密等。
-
多语言支持:Minio 支持多种编程语言,包括 Java、Python、Ruby 和 Go 等。
-
社区支持:Minio 是一个开源项目,拥有庞大的社区支持和贡献者。它的源代码可以在 - GitHub 上获得,并且有一个活跃的邮件列表和论坛。
-
对象存储:Minio 的核心功能是对象存储。它允许用户上传和下载任意数量和大小的对象,并- 提供了多种 API 和 SDK 来访问这些对象。
-
块存储:Minio 还支持块存储,允许用户上传和下载大型文件(例如图像或视频)。块存储是一- 种快速、高效的方式来处理大型文件。
-
文件存储:Minio 还支持文件存储,允许用户上传和下载单个文件。文件存储是一种简单、快速的方式来处理小型文件。
使用 minio 官方提供的 Java SDK 进行操作。
Minio 官方文档:https://min.io/docs/minio/linux/developers/java/minio-java.html
介绍一下雪花 ID 的算法,假如要你实现一个全球唯一的 id 你会怎么做
雪花算法是一种分布式 ID 生成方案,它可以生成一个长度为 64 位的唯一 ID,其中包含了时间戳、数据中心 ID 和机器 ID 等信息。
雪花算法的核心思想是利用时间戳和机器 ID 生成一个唯一的序列号,从而保证生成的 ID 的唯一性。
雪花算法的优点包括唯一性、时间戳有序和高性能,缺点包括依赖时钟和数据中心 ID 和机器 ID 需要手动分配。
全球唯一 ID 目前有两种方案:
-
基于时间的:能基本保证全球唯一性,但是使用了 Mac 地址,会暴露 Mac 地址和生成时间。
-
分布式的:能保证全球唯一性,但是常用库基本没有实现。
具体可参考 https://www.developers.pub/article/606
项目里“楼中楼”评论是如何做的?
每条评论加一个类似parentId和replyId字段。
- 直接发表评论,则
parentId和replyId都为空 - 对一级评论回复,则
parentId和replyId都为一级评论的id - 楼中楼进行回复,
parentId为一级评论的id,replyId为回复的评论的id
如何统计一天之内登录过的人数?
两种基于 Redis 的方案:
基于 BitSet
用户登录时,使用setbit命令记录用户已登录。
例子:
setbit login:<日期> <用户id> 1
然后使用bitcount统计今日的数量。
例子:
bitcount login:<日期>
注意点: 统计的时间复杂度为 O(N) ,当进行大数据量的统计时,最好将任务指派到附属节点(slave)进行,避免阻塞主节点。
优点: 精准统计,基本上是秒出结果,能方便地获取统计对象的状态。
缺点: 数量十分巨大时,空间占用会比较,可以通过分片,或者压缩等手段去解决。
基于 HyperLogLog
用户登录时,使用pfadd命令记录用户已登录。
例子:
pffadd login_<日期> <用户id>
然后使用pfcount统计今日的数量。
例子:
pfcount login_<日期>
注意点: key 不能用:分隔,可使用_代替
优点: 可以统计海量数量,并且占用内存很小。
缺点: 牺牲了准确率,而且无法得到每个统计对象的状态。
Bitmap 存储一亿数据需要 12M,而 HyperLogLog 只需要 14K。
说一说 MySQL 索引
java 内存模型了解过吗
JVM 堆栈内存(什么是虚拟机栈)
每个线程都有自己的一个虚拟机栈,虚拟机栈保存着方法的局部变量、部分结果,并参与方法的调用和返回,生命周期和所属的线程一致。每个虚拟机栈中都有一个个的栈帧( Stack Frame),每个栈帧对应一次方法调用。
栢码视频:https://www.bilibili.com/video/BV1Er4y1r7as?p=8
堆栈内存相关的异常
如果线程请求分配的栈容量超过允许的最大容量,将会抛出StackOverflowError异常。
如果 Java 虚拟机栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存,或者在创建新的线程时没有足够的内存去创建对应的虚拟机栈,将会抛出一个
OutOfMemoryError异常。
Java 并发,多线程知道吗?
synchronized 实现原理了解吗?锁升级?乐观锁?
线程池的拒绝策略都有什么?
Spring 的扩展你有了解过吗?有没有自己编写过 starter?
Spring的事务传播特性
以下内容施工中
Redis过期了任务还没执行完怎么办?
写在消息队列里面异步更新redis
查询一个不是主键的索引,需要回表几次?
慢查询是什么?如何查询?
开启MySQL慢查询日志、explain关键字
主从复制原理知道吗?
项目里的客户端都采集服务器的什么信息了?
Spring的事务传播特性?
Spring的事务你用过吗?
那@Transactional的原理呢?
什么情况会导致事务的失效?
你项目里是如何保证Redis和数据库的最终一致性的?
Redis持久化你项目里用了吗?
说一下RabbitMQ里面的角色吧?
如何保证消息不丢失?
消息积压怎么办?
你简历里项目是怎么部署到服务器的?(docker镜像)
Markdown 语法速查
文章最后更新:2024-01-07

基本语法
大部分编辑器都支持的基本语法
标题
# 一级标题
## 二级标题
## 三级标题
段落
这是一段文字
这是另一段文字
换行
第一行
第二行
或者
第一行<br>
第二行
强调
**粗体**
_斜体_
**_粗斜体_**
~~删除线~~
引用
> 引用的一段话
>
> 引用
列表
有序列表:
1. 苹果
2. 香蕉
3. 橘子
1. 红色火龙果
2. 白色火龙果
4. 梨子
无序列表:
- 张三
- 李四
- 王五
- 一
- 二
- 三
- ...
代码块
`console.log('hello')`
```js
const str = 'hello'
console.log(str)
```
分割线
上面的文字
---
下面的文字
链接
一般链接:
[Markdown 语法](https://markdown.com.cn "链接标题")
简易链接:
<https://markdown.com.cn>
<fake@example.com>
格式化链接:
加粗文字 **[EFF](https://eff.org)**.
斜体字 _[Markdown Guide](https://www.markdownguide.org)_.
代码块 [`code`](#code).
图片

可点击的图片:
[](链接)
转义字符
\*
扩展语法
扩展语法并不是所有编辑器都支持
表格
| 左对齐 | 居中 | 右对齐 |
|---|---|---|
| Header | Title | Here's this |
| Paragraph | Text | | And more |
| 左对齐 | 居中 | 右对齐 |
| :-------- | :---------: | ----------: |
| Header | Title | Here's this |
| Paragraph | Text | | And more |
任务列表
- Write the press release
- Update the website
- Contact the media
- [x] Write the press release
- [ ] Update the website
- [ ] Contact the media
latex
$\pi = 3.14159$
$$ \pi = 3.14159 $$
$\pi = 3.14159$
$$
\pi = 3.14159
$$
mermaid
flowchart TD
Start --> Stop
```mermaid
flowchart TD
Start --> Stop
```
Starship 安装配置
文章最后更新:2023-08-15
配置文件
配置文件位置: ~/.config/starship.toml
本地终端配置
"$schema" = 'https://starship.rs/config-schema.json'
add_newline = false
format = """
[](#9A348E)\
$os$hostname\
[](bg:#DA627D fg:#9A348E)\
$directory\
[](fg:#DA627D bg:#FCA17D)\
$git_branch\
$git_status\
[](fg:#FCA17D bg:#86BBD8)\
$c$elixir$elm$golang$gradle$haskell$java$julia$nodejs$nim$rust$scala\
[](fg:#86BBD8 bg:#06969A)\
$docker_context\
[](fg:#06969A bg:#33658A)\
$time\
[ ](fg:#33658A)\
$line_break\
$username$character"""
[aws]
format = '[ $symbol($profile)(\($region\))($duration )]($style)'
symbol = " "
[bun]
format = '[ $symbol($version)]($style)'
[buf]
format = '[ $symbol($version(-$name))]($style)'
symbol = " "
[c]
style = "bg:#86BBD8 white"
format = '[ $symbol($version(-$name))]($style)'
symbol = " "
[character]
success_symbol = '[➜](bold green)'
error_symbol = '[➜](bold red)'
[cmake]
format = '[ $symbol($version)]($style)'
[conda]
format = '[ $symbol$environment]($style)'
symbol = " "
[cmd_duration]
format = '[ $duration]($style)'
[cobol]
format = '[ $symbol($version)]($style)'
[crystal]
format = '[ $symbol($version)]($style)'
[daml]
format = '[ $symbol($version)]($style)'
[dart]
format = '[ $symbol($version)]($style)'
symbol = " "
[deno]
format = '[ $symbol($version)]($style)'
[directory]
style = "bg:#DA627D white"
format = "[ $path$read_only ]($style)"
truncation_length = 3
truncation_symbol = "…/"
read_only = " "
[directory.substitutions]
"~" = ""
"repos" = ""
"Desktop" = ""
"Documents" = ""
"Downloads" = ""
"Music" = ""
"Videos" = ""
"Pictures" = ""
[docker_context]
style = "bg:#06969A white"
format = '[ $symbol$context]($style)'
symbol = " "
[dotnet]
format = '[ $symbol($version)(🎯 $tfm)]($style)'
[elixir]
style = "bg:#86BBD8"
format = '[ $symbol($version \(OTP $otp_version\))]($style)'
symbol = " "
[elm]
style = "bg:#86BBD8 white"
format = '[ $symbol($version)]($style)'
symbol = " "
[erlang]
format = '[ $symbol($version)]($style)'
[gcloud]
format = '[ $symbol$account(@$domain)(\($region\))]($style)'
[git_branch]
style = "bg:#FCA17D white"
format = '[ $symbol$branch]($style)'
symbol = " "
[git_status]
style = "bg:#FCA17D white"
format = '[ $all_status$ahead_behind ]($style)'
[golang]
style = "bg:#86BBD8 white"
format = '[ $symbol($version) ]($style)'
symbol = " "
[gradle]
style = "bg:#86BBD8 white"
format = '[ $symbol ($version) ]($style)'
[haskell]
style = "bg:#86BBD8 white"
format = '[ $symbol($version)]($style)'
symbol = " "
[helm]
format = '[ $symbol($version)]($style)'
[hg_branch]
format = '[ $symbol$branch]($style)'
symbol = " "
[hostname]
ssh_only = false
format = '[ $hostname ](bg:#9A348E white)'
disabled = false
[java]
style = "bg:#86BBD8 white"
format = '[ $symbol($version)]($style)'
symbol = " "
[julia]
style = "bg:#86BBD8 white"
format = '[ $symbol($version)]($style)'
symbol = " "
[kotlin]
format = '[ $symbol($version)]($style)'
[kubernetes]
format = '[ $symbol$context( \($namespace\))]($style)'
[lua]
format = '[ $symbol($version)]($style)'
[memory_usage]
format = '$symbol[$ram( | $swap)]($style)'
symbol = " "
[nim]
style = "bg:#86BBD8 white"
format = '[ $symbol($version)]($style)'
symbol = " "
[nix_shell]
format = '[ $symbol$state( \($name\))]($style)'
symbol = " "
[nodejs]
style = "bg:#86BBD8 white"
format = '[ $symbol($version) ]($style)'
symbol = " "
[ocaml]
format = '[ $symbol($version)(\($switch_indicator$switch_name\))]($style)'
[openstack]
format = '[ $symbol$cloud(\($project\))]($style)'
[os]
style = 'bg:#9A348E white'
disabled = false
[os.symbols]
Windows = ""
Debian = ""
[package]
format = '[ $symbol$version]($style)'
symbol = " "
[perl]
format = '[ $symbol($version)]($style)'
[php]
format = '[ $symbol($version)]($style)'
[pulumi]
format = '[ $symbol$stack]($style)'
[purescript]
format = '[ $symbol($version)]($style)'
[python]
format = '[ ${symbol}${pyenv_prefix}(${version})(\($virtualenv\))]($style)'
symbol = " "
[raku]
format = '[ $symbol($version-$vm_version)]($style)'
[red]
format = '[ $symbol($version)]($style)'
[ruby]
format = '[ $symbol($version)]($style)'
[rust]
style = "bg:#86BBD8 white"
format = '[ $symbol($version)]($style)'
symbol = " "
[scala]
style = "bg:#86BBD8 white"
format = '[ $symbol($version)]($style)'
[spack]
format = '[ $symbol$environment]($style)'
symbol = "🅢 "
[sudo]
format = '[ as $symbol] '
[swift]
format = '[ $symbol($version)]($style)'
[terraform]
format = '[ $symbol$workspace]($style)'
[time]
disabled = false
time_format = "%T"
style = "bg:#33658A white"
format = '[ $time ]($style)'
[username]
show_always = true
format = '[$user ]($style)'
disabled = false
[vagrant]
format = '[ $symbol($version)]($style)'
[vlang]
format = '[ $symbol($version)]($style)'
[zig]
format = '[ $symbol($version)]($style)'
服务终端配置
"$schema" = 'https://starship.rs/config-schema.json'
add_newline = false
[character]
success_symbol = "[>](bold green)"
error_symbol = "[x](bold red)"
vicmd_symbol = "[<](bold green)"
[git_commit]
tag_symbol = " tag "
[git_status]
ahead = ">"
behind = "<"
diverged = "<>"
renamed = "r"
deleted = "x"
[aws]
symbol = "aws "
[bun]
symbol = "bun "
[c]
symbol = "C "
[cobol]
symbol = "cobol "
[conda]
symbol = "conda "
[crystal]
symbol = "cr "
[cmake]
symbol = "cmake "
[daml]
symbol = "daml "
[dart]
symbol = "dart "
[deno]
symbol = "deno "
[dotnet]
symbol = ".NET "
[directory]
read_only = " ro"
[docker_context]
symbol = "docker "
[elixir]
symbol = "exs "
[elm]
symbol = "elm "
[git_branch]
symbol = "git "
[golang]
symbol = "go "
[hg_branch]
symbol = "hg "
[java]
symbol = "java "
[julia]
symbol = "jl "
[kotlin]
symbol = "kt "
[lua]
symbol = "lua "
[nodejs]
symbol = "nodejs "
[memory_usage]
symbol = "memory "
[nim]
symbol = "nim "
[nix_shell]
symbol = "nix "
[ocaml]
symbol = "ml "
[package]
symbol = "pkg "
[perl]
symbol = "pl "
[php]
symbol = "php "
[pulumi]
symbol = "pulumi "
[purescript]
symbol = "purs "
[python]
symbol = "py "
[raku]
symbol = "raku "
[ruby]
symbol = "rb "
[rust]
symbol = "rs "
[scala]
symbol = "scala "
[spack]
symbol = "spack "
[sudo]
symbol = "sudo "
[swift]
symbol = "swift "
[terraform]
symbol = "terraform "
[zig]
symbol = "zig "
施工中...
系统运维和操作笔记
文章最后更新:2024-11-21

vim 配置文件
set nocompatible
syntax on
set showmode
set showcmd
set mouse=a
set encoding=utf-8
set t_Co=256
filetype indent on
set autoindent
set expandtab
set tabstop=4
set shiftwidth=4
set softtabstop=4
set smartindent
filetype plugin indent on
set number
"set relativenumber
"set cursorline
set nowrap
"set textwidth=80
"set wrap
"set linebreak
"set wrapmargin=2
set scrolloff=3
set sidescrolloff=10
set laststatus=2
set ruler
set showmatch
set hlsearch
set incsearch
set ignorecase
set smartcase
set undofile
set undodir=~/.vim/.undo//
set autochdir
set noerrorbells
"set visualbell
set belloff=all
set history=1000
set autoread
set listchars=tab:»\ ,trail:·
set list
set wildmenu
set wildmode=longest:list,full
Dockerfile 示例
Spring Boot 应用
LABEL maintainer="Demo Docker Image"
# 构建用镜像
FROM maven:3.8.6-eclipse-temurin-17-alpine AS build
# 指定构建过程中的工作目录
WORKDIR /build
# 将src目录下所有文件,拷贝到工作目录中src目录下
COPY src /build/src
# 拷贝配置文件
COPY pom.xml /build
# 执行代码编译命令
RUN mvn mvn -f /build/pom.xml clean package -Dmaven.test.skip=true
# 运行时镜像
FROM eclipse-temurin:17-jre AS RUN
# 指定运行时的工作目录
WORKDIR /app
# 设置数据卷
VOLUME /app/data
# 将构建产物jar包拷贝到运行时目录中
COPY --from=build /build/target/*.jar ./springboot.jar
# 暴露端口
EXPOSE 8080
# 执行启动命令
CMD ["java","-Xms512M", "-Xmx512M", "-jar", "/app/springboot.jar"]
Caddy 常用配置文件
{
# 关闭管理面板
admin off
}
# 通用配置块
(COMMON_CONFIG) {
# tls 配置
#tls /etc/caddy/flapypan.cn.pem /etc/caddy/flapypan.cn.key
# 压缩支持 (br 需要额外插件)
encode zstd br gzip
# HSTS 推荐的时间是 2 年
header Strict-Transport-Security "max-age=63072000; includeSubDomains"
# 去除响应头
header -Server
header -Via
header -Server
header -x-powered-by
# 禁止部分爬虫的ua
@norobots {
header_regexp User-Agent "^(|360Spider|JikeSpider|Spider|spider|bot|Bot|2345Explorer|curl|wget|webZIP|qihoobot|Baiduspider|Googlebot(-Mobile|-Image)?|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp( China)?|YoudaoBot|Sosospider|Sogou( spider| web spider)|MSNBot|ia_archiver|Tomato Bot|NSPlayer|bingbot)?$"
}
redir @norobots http://localhost/ permanent includeSubDomains"
}
# 站点配置
example.org {
# 重定向到www
redir https://www.example.org{uri}
import COMMON_CONFIG
}
blog.example.org {
# 重定向到www
redir https://www.example.org{uri}
import COMMON_CONFIG
}
www.example.org {
root * /home/user/blog/dist
route {
# handle_path 去除前缀,handle 保留
handle_path /api/* {
# 反向代理
reverse_proxy localhost:8080
}
# 单页面应用
try_files {path}.html {path} /
file_server
}
import COMMON_CONFIG
}
FFmpeg 常用指令
基础用法
ffmpeg [全局参数] [输入文件参数] -i [输入文件] [输出文件参数] [输出文件]
完整示例
ffmpeg -y \
# 使用qsv硬件解码
-hwaccel qsv -hwaccel_output_format qsv -init_hw_device qsv=hw \
-i [input] \
# 音频编码器
# libx264 h264_nvenc h264_qsv libx265 hevc_qsv libvpx-vp9 vp9_qsv libaom-av1
-c:a copy \
# 视频编码器
-c:v copy \
# 质量
-preset slow\
# 码率
-minrate 964K -maxrate 3856K -bufsize 2000K \
# 720p
-vf scale=720:-1 \
# 去除流
-an -vn \
[output]
查看支持的编码器
ffmpeg -encoders
查看支持的容器格式(后缀名)
ffmpeg -formats
快速转换格式
# 转换 png 为 webp
ffmpeg -y -i input.png output.webp
# 转换 avi 为 mp4
ffmpeg -y -i input.avi output.mp4
多个输入合并
ffmpeg -y -i input.aac -i input.mp4 output.mp4
截图(从 1:24 开始,每秒一张)
ffmpeg -y -i input.mp4 -ss 00:01:24 -t 00:00:01 output\_%3d.jpg
截图(某一帧)
ffmpeg -ss 01:23:45 -i input.mp4 -vframes 1 \
# 质量(1-5,1最高质量)
-q:v 2 \
output.jpg
裁剪
ffmpeg -ss [开始时间] -i [input] -t [持续时间] -c copy [output]
ffmpeg -ss [开始时间] -i [input] -to [结束时间] -c copy [output]
音频添加图片输出视频
ffmpeg \
-loop 1 \
-i cover.jpg -i input.mp3 \
-c:v libx264 -c:a aac -b:a 192k -shortest \
output.mp4
logback 配置文件大全
<?xml version="1.0" encoding="UTF-8"?>
<!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL,如果设置为WARN,则低于WARN的信息都不会输出 -->
<!-- scan:当此属性设置为true时,配置文档如果发生改变,将会被重新加载,默认值为true -->
<!-- scanPeriod:设置监测配置文档是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。 当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<configuration scan="true" scanPeriod="10 seconds">
<contextName>logback</contextName>
<!-- 文件切割大小 -->
<property name="maxFileSize" value="500MB"/>
<!-- 文档保留天数 -->
<property name="maxHistory" value="20"/>
<!-- 文档保留总大小 -->
<property name="totalSizeCap" value="50GB"/>
<!-- name的值是变量的名称,value的值时变量定义的值。通过定义的值会被插入到logger上下文中。定义后,可以使“${}”来使用变量。 -->
<property name="log.path" value="logs"/>
<!--0. 日志格式和颜色渲染 -->
<!-- 彩色日志依赖的渲染类 -->
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/>
<conversionRule conversionWord="wex"
converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter"/>
<conversionRule conversionWord="wEx"
converterClass="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter"/>
<!-- 彩色日志格式 -->
<property name="CONSOLE_LOG_PATTERN"
value="${CONSOLE_LOG_PATTERN:-%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/>
<!--1. 输出到控制台-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--此日志appender是为开发使用,只配置最底级别,控制台输出的日志级别是大于或等于此级别的日志信息-->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>debug</level>
</filter>
<encoder>
<Pattern>${CONSOLE_LOG_PATTERN}</Pattern>
<!-- 设置字符集 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!--2. 输出到文档-->
<!-- 2.1 level为 DEBUG 日志,时间滚动输出 -->
<appender name="DEBUG_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文档的路径及文档名 -->
<file>${log.path}/debug.log</file>
<!--日志文档输出格式-->
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
<charset>UTF-8</charset> <!-- 设置字符集 -->
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 日志归档 -->
<fileNamePattern>${log.path}/debug-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>60</maxHistory>
<totalSizeCap>20GB</totalSizeCap>
</rollingPolicy>
<!-- 此日志文档只记录debug级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>debug</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 2.2 level为 INFO 日志,时间滚动输出 -->
<appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文档的路径及文档名 -->
<file>${log.path}/info.log</file>
<!--日志文档输出格式-->
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 日志归档 -->
<fileNamePattern>${log.path}/info-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>60</maxHistory>
<totalSizeCap>20GB</totalSizeCap>
</rollingPolicy>
<!-- 此日志文档只记录info级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>info</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 2.3 level为 WARN 日志,时间滚动输出 -->
<appender name="WARN_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文档的路径及文档名 -->
<file>${log.path}/warn.log</file>
<!--日志文档输出格式-->
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 日志归档 -->
<fileNamePattern>${log.path}/warn-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>60</maxHistory>
<totalSizeCap>20GB</totalSizeCap>
</rollingPolicy>
<!-- 此日志文档只记录warn级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>warn</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 2.4 level为 ERROR 日志,时间滚动输出 -->
<appender name="ERROR_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文档的路径及文档名 -->
<file>${log.path}/error.log</file>
<!--日志文档输出格式-->
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 日志归档 -->
<fileNamePattern>${log.path}/error-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>60</maxHistory>
<totalSizeCap>20GB</totalSizeCap>
</rollingPolicy>
<!-- 此日志文档只记录ERROR级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!--
<logger>用来设置某一个包或者具体的某一个类的日志打印级别、以及指定<appender>。<logger>仅有一个name属性, 一个可选的level和一个可选的addtivity属性。
name:用来指定受此logger约束的某一个包或者具体的某一个类。
level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF,
还有一个特俗值INHERITED或者同义词NULL,代表强制执行上级的级别。
如果未设置此属性,那么当前logger将会继承上级的级别。
addtivity:是否向上级logger传递打印信息。默认是true。
<logger name="org.springframework.web" level="info"/>
<logger name="org.springframework.scheduling.annotation.ScheduledAnnotationBeanPostProcessor" level="INFO"/>
-->
<!--减少SpringBoot自动配置的日志信息-->
<logger name="org.springframework.boot.autoconfigure" level="WARN"/>
<!--打印SQL日志信息-->
<logger name="org.mybatis.spring" level="DEBUG"/>
<!--<logger name="DAO" level="DEBUG"/>-->
<!--
root节点是必选节点,用来指定最基础的日志输出级别,只有一个level属性
level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF,不能设置为INHERITED或者同义词NULL。默认是DEBUG
,标识这个appender将会添加到这个logger。
-->
<root level="info">
<appender-ref ref="CONSOLE"/>
<!-- <appender-ref ref="DEBUG_FILE"/>-->
<!-- <appender-ref ref="INFO_FILE" />-->
<appender-ref ref="WARN_FILE"/>
<!-- <appender-ref ref="ERROR_FILE" />-->
</root>
</configuration>
Windows 使用笔记
文章最后更新:2024-07-16

删除 win11 中资源管理器左侧的主文件夹和图库
Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\Software\Classes\CLSID\{e88865ea-0e1c-4e20-9aa6-edcd0212c87c}]
"System.IsPinnedToNameSpaceTree"=dword:00000000
[-HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Desktop\NameSpace\{f874310e-b6b7-47dc-bc84-b9e6b38f5903}]
解决打开游戏时出现“无法打开此“ms-gamingoverlay"链接”弹窗问题
-
打开运行(Win+R),并输入
regedit命令,按确定或回车 -
定位如下位置:
HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\GameDVR
找到AppCaptureEnabled这个键值,把值改为 0
- 定位如下位置:
HKEY_CURRENT_USER\System\GameConfigStore
找到 GameDVR_Enabled 这个键值,把值改为 0
解决 ping localhost 时为 ipv6 地址
解决方法
请在管理员权限的 cmd 或 powershell 中运行
先查一下前缀优先级:
netsh interface ipv6 show prefixpolicies
Querying active state...
Precedence Label Prefix
---------- ----- --------------------------------
50 0 ::1/128
40 1 ::/0
35 4 ::ffff:0:0/96
30 2 2002::/16
5 5 2001::/32
3 13 fc00::/7
1 11 fec0::/10
1 11 3ffe::/16
1 3 ::/96
上面的输出中 ::/0 是 ipv6 的前缀,需要调低优先级,低于 ::ffff:0:0/96 ::/96 这些 ipv4 的前缀即可。
依次执行:
netsh int ipv6 set prefix ::/96 50 0
netsh int ipv6 set prefix ::ffff:0:0/96 40 1
netsh int ipv6 set prefix 2002::/16 35 2
netsh int ipv6 set prefix 2001::/32 30 3
netsh int ipv6 set prefix ::1/128 10 4
netsh int ipv6 set prefix ::/0 5 5
netsh int ipv6 set prefix fc00::/7 3 13
netsh int ipv6 set prefix fec0::/10 1 11
netsh int ipv6 set prefix 3ffe::/16 1 12
再次查询:
Querying active state...
Precedence Label Prefix
---------- ----- --------------------------------
50 0 ::/96
40 1 ::ffff:0:0/96
35 2 2002::/16
30 3 2001::/32
10 4 ::1/128
5 5 ::/0
3 13 fc00::/7
1 12 3ffe::/16
1 11 fec0::/10
前缀含义
Windows10/11 的访问前缀规则参照 RFC6724: Default Address Selection for Internet Protocol Version 6 (IPv6) 实现。
可参考 在 IANA IPv6 Special-Purpose Address Registry 查看这些前缀的归属。
优化 Windows Defender 性能
设置扫描占用的 CPU 比例
查看当前的 CPU 占用比例,默认一般是 50
Get-MpPreference | select ScanAvgCPULoadFactor
调整 CPU 占用比例,例如设置为 20
Set-MpPreference -ScanAvgCPULoadFactor 20
关闭映射磁盘文件扫描
Set-MpPreference -DisableScanningNetworkFiles 1
Set-MpPreference -DisableScanningMappedNetworkDrivesForFullScan 1
彻底关闭 Hyper-V、WSL、Device Guard、Credential Guard
关闭下列基于虚拟化的相关服务和模块以提升性能
注意: WSL2、Docker Desktop、Podman Desktop 等基于 Hyper-V 的软件将无法工作
反正我不用这些软件
关闭 Hyper-V 以及相关服务
首先在终端管理员中关闭 Hyper-V
Disable-WindowsOptionalFeature -Online -FeatureName Microsoft-Hyper-V-Hypervisor
bcdedit /set hypervisorlaunchtype off
再进入 Windows 功能关闭其他功能
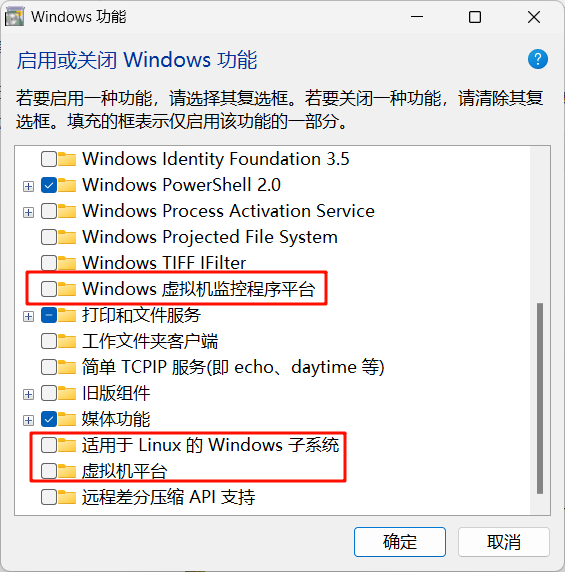
关闭内存完整性
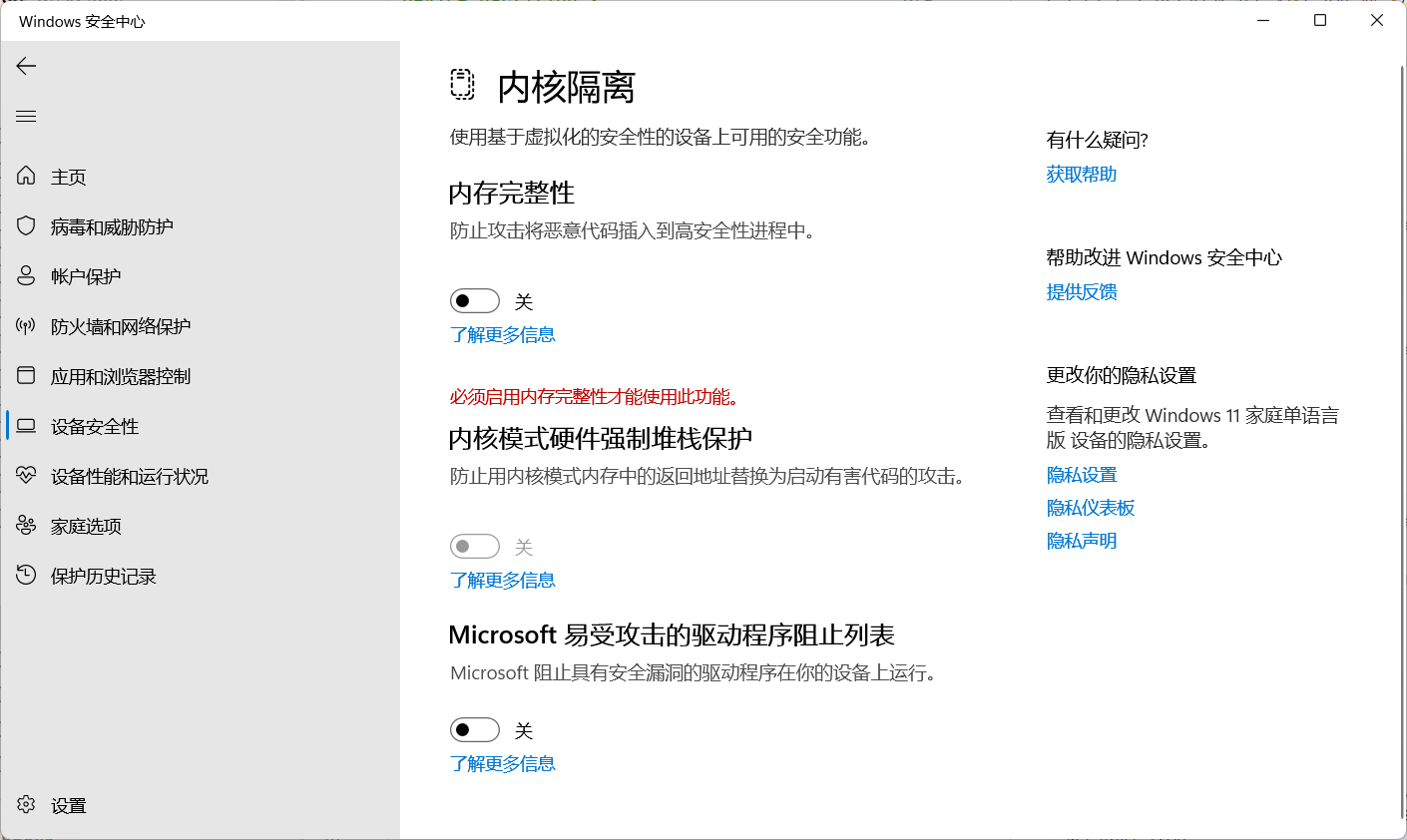
关闭 Device Guard
进入注册表
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\DeviceGuard
EnableVirtualizationBasedSecurity = 0
RequirePlatformSecurityFeatures = 0
关闭 Credential Guard
进入注册表
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Lsa
LsaCfgFlags = 0
HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\Windows\DeviceGuard
LsaCfgFlags = 0
进入管理员 CMD
bcdedit /set vsmlaunchtype off
mountvol X: /s
copy %WINDIR%\System32\SecConfig.efi X:\EFI\Microsoft\Boot\SecConfig.efi /Y
bcdedit /create {0cb3b571-2f2e-4343-a879-d86a476d7215} /d "DebugTool" /application osloader
bcdedit /set {0cb3b571-2f2e-4343-a879-d86a476d7215} path "\EFI\Microsoft\Boot\SecConfig.efi"
bcdedit /set {bootmgr} bootsequence {0cb3b571-2f2e-4343-a879-d86a476d7215}
bcdedit /set {0cb3b571-2f2e-4343-a879-d86a476d7215} loadoptions DISABLE-LSA-ISO,DISABLE-VBS
bcdedit /set {0cb3b571-2f2e-4343-a879-d86a476d7215} device partition=X:
mountvol X: /d
重启电脑后会提示关闭 Credential Guard,按 Win + F3 确认
安装开启 Hyper-V
pushd "%~dp0"
dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txt
for /f %%i in ('findstr /i . hyper-v.txt 2^>nul') do dism /online /norestart /add-package:"%SystemRoot%\servicing\Packages\%%i"
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALL
重新编译 .net framework 机器码
$env:PATH = [Runtime.InteropServices.RuntimeEnvironment]::GetRuntimeDirectory()
[AppDomain]::CurrentDomain.GetAssemblies() | ForEach-Object {
$path = $_.Location
if ($path) {
$name = Split-Path $path -Leaf
Write-Host -ForegroundColor Yellow "`r`n$name"
ngen.exe install $path /nologo
}
}
清除图标缓存
taskkill /f /im explorer.exe
cd /d %userprofile%\AppData\Local\Microsoft\Windows\Explorer
attrib -h iconcache_*.db
del iconcache_*.db /a
CD /d %userprofile%\AppData\Local
DEL IconCache.db /a
start explorer
start explorer.exe
cho 执行完成
安装开启组策略
@echo off
pushd "%~dp0"
dir /b C:\Windows\servicing\Packages\Microsoft-Windows-GroupPolicy-ClientExtensions-Package~3*.mum >List.txt
dir /b C:\Windows\servicing\Packages\Microsoft-Windows-GroupPolicy-ClientTools-Package~3*.mum >>List.txt
for /f %%i in ('findstr /i . List.txt 2^>nul') do dism /online /norestart /add-package:"C:\Windows\servicing\Packages\%%i"
pause
powershell 配置
$Env:POWERSHELL_UPDATECHECK="LTS"
$OutputEncoding = [console]::InputEncoding = [console]::OutputEncoding = New-Object System.Text.UTF8Encoding
Import-Module PSReadLine
Set-PSReadLineOption -Colors @{
Command = [ConsoleColor]::Blue
Comment = [ConsoleColor]::DarkGray
ContinuationPrompt = [ConsoleColor]::White
Default = [ConsoleColor]::White
Emphasis = [ConsoleColor]::Cyan
Error = [ConsoleColor]::Red
InlinePrediction = [ConsoleColor]::DarkGray
Keyword = [ConsoleColor]::DarkBlue
ListPrediction = [ConsoleColor]::DarkGray
ListPredictionSelected = "$([char]0x1b)[30;47m"
Member = [ConsoleColor]::Magenta
Number = [ConsoleColor]::Blue
Operator = [ConsoleColor]::White
Parameter = [ConsoleColor]::White
String = [ConsoleColor]::DarkGreen
'Type' = [ConsoleColor]::Green
Variable = [ConsoleColor]::Yellow
}
Set-PSReadLineOption -PredictionSource History
Set-PSReadLineOption -HistorySearchCursorMovesToEnd
Set-PSReadLineKeyHandler -Key "Tab" -Function MenuComplete
Set-PSReadlineKeyHandler -Key "Ctrl+d" -Function ViExit
Set-PSReadLineKeyHandler -Key "Ctrl+z" -Function Undo
Set-PSReadLineKeyHandler -Key UpArrow -Function HistorySearchBackward
Set-PSReadLineKeyHandler -Key DownArrow -Function HistorySearchForward
function ListDirectory {
(Get-ChildItem).Name
Write-Host("")
}
Set-Alias -Name ls -Value ListDirectory -Option AllScope
Set-Alias -Name ll -Value Get-ChildItem -Option AllScope
function OpenCurrentFolder {
param
(
$Path = '.'
)
Invoke-Item $Path
}
Set-Alias -Name open -Value OpenCurrentFolder -Option AllScope
Set-Alias -Name pn -Value pnpm -Option AllScope
Invoke-Expression (&starship init powershell)
Web 笔记
文章最后更新:2024-07-10
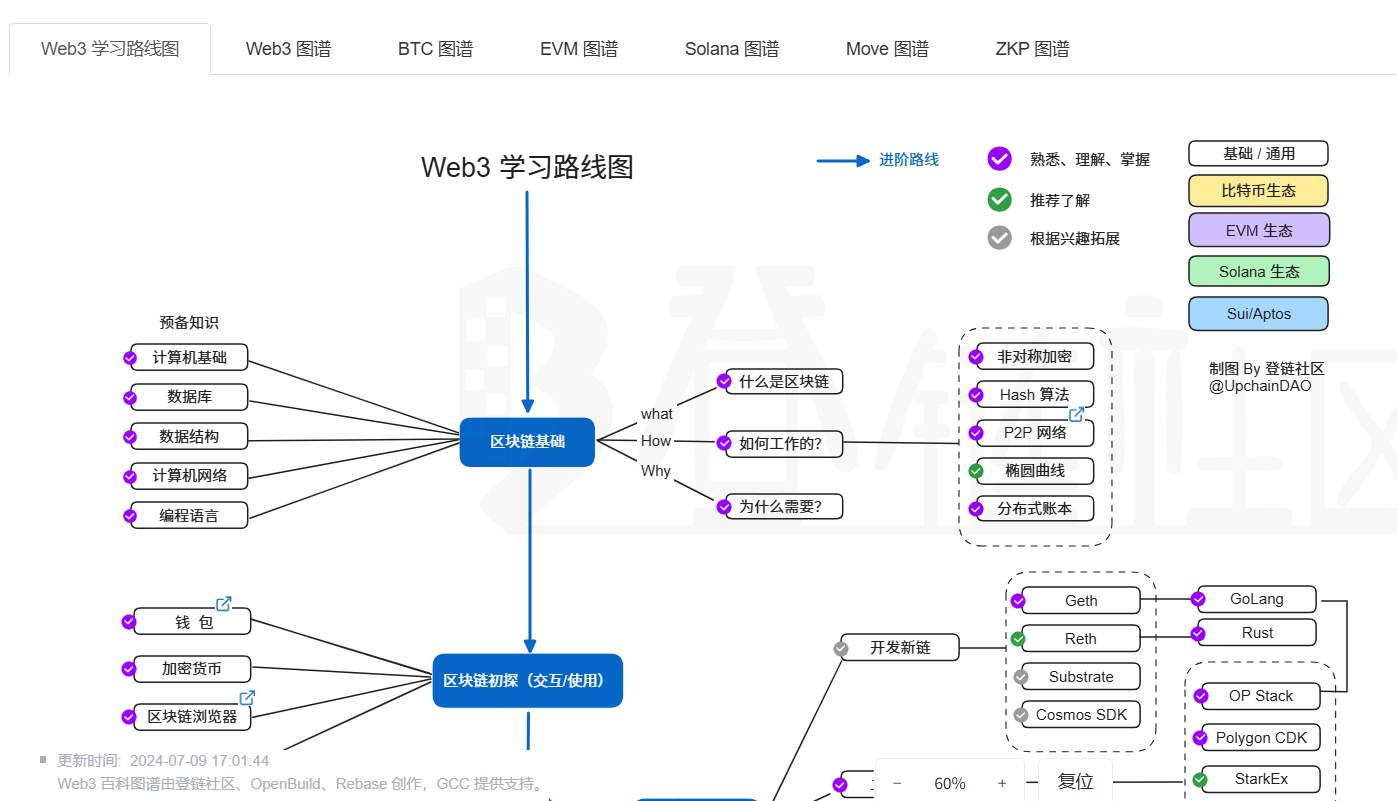
Web 3 学习路线图
https://learnblockchain.cn/maps/Roadmap
检测浏览器的巧妙方法
通常,我们检测浏览器是通过获取 navigator.userAgent,但 ua 是可以通过浏览器设置或浏览器插件人为更改的,这种方法就不够准确。
这里推荐两个巧妙的方法:
ComputedStyle 检测 CSS 前缀
/**
* 获取所有 ComputedStyle 检测 CSS 前缀
*/
function detectBrowserByComputedStyle() {
const computedStyle = window.getComputedStyle(document.documentElement, '')
const prefix = Array.prototype.slice.call(computedStyle).join('').match(/-(moz|webkit|ms)-/)[1]
return {
webkit: prefix === 'webkit',
moz: prefix === 'moz',
ms: prefix === 'ms',
o: prefix === 'o',
}
}
检测 js 的相关功能
/**
* 通过 feature 检测浏览器
*/
function detectBrowserByFeature() {
// Opera 8.0+
const isOpera = (!!window.opr && !!opr.addons) || !!window.opera || navigator.userAgent.indexOf(' OPR/') >= 0
// Firefox 1.0+
const isFirefox = typeof InstallTrigger !== 'undefined'
// Safari 3.0+
const isSafari = /constructor/i.test(window.HTMLElement)
|| ((typeof safari !== 'undefined' && window['safari'].pushNotification)).toString() ===
'[object SafariRemoteNotification]'
// Internet Explorer 6-11
const isIE = !!window.ActiveXObject || 'ActiveXObject' in window || !!document.documentMode
// 旧 Edge 20+
const isEdge = !isIE && !!window.StyleMedia
// Chrome 1 - 79
const isChrome = !!window.chrome
// 新 Edge
const isEdgeChromium = isChrome && (navigator.userAgent.indexOf('Edg') != -1)
// Blink 渲染引擎
const isBlink = (isChrome || isOpera) && !!window.CSS
return {
isOpera, isFirefox, isSafari, isIE, isEdge, isChrome, isEdgeChromium, isBlink,
}
}
HTML 防蜘蛛
都是防君子不防小人的方法
使用 HTML 标签,告诉搜索引擎不需要索引
<meta name="robots" content="noindex, nofollow"/>
使用 robots.txt
User-agent: *
Disallow: *
Vue 笔记
文章最后更新:2024-04-16

复制内容添加水印
封装了一个 vue 的 hook,类似 csdn 的那种在复制文本时候添加特殊的水印,并且复制不会丢失原格式。
代码
/**
* 复制文本添加水印
* @param {HTMLElement|import('content/post/note/vue').Ref<HTMLElement>|import('vue').ComputedRef<HTMLElement>} target 监听的元素
* @param {string|import('content/post/note/vue').Ref<string>|import('vue').ComputedRef<string>} watermark 水印内容(html格式)
* @param {string|import('content/post/note/vue').Ref<string>|import('vue').ComputedRef<string>} [fallbackWatermark] 不支持html的回滚水印内容(文本格式)
* @param {number|import('content/post/note/vue').Ref<number>|import('vue').ComputedRef<number>} [minTextLength] 添加水印的阈值
*/
export default function useCopyWatermark(target, { watermark, fallbackWatermark, minTextLength } = {}) {
const watermarkText = computed(() => {
const unwrappedFallbackWatermark = unref(fallbackWatermark)
if (unwrappedFallbackWatermark) return unwrappedFallbackWatermark
const watermarkEle = document.createElement('div')
watermarkEle.innerHTML = unref(watermark)
return watermarkEle.innerText
})
const copyHandler = (evt) => {
const selection = window.getSelection()
if (selection.toString().length < unref(minTextLength ?? 200)) return
const helper = document.createElement('div')
helper.appendChild(selection.getRangeAt(0).cloneContents())
evt.clipboardData.setData('text/plain', helper.innerText + watermarkText.value)
evt.clipboardData.setData('text/html', helper.innerHTML + unref(watermark))
evt.preventDefault()
}
onMounted(() => unref(target)?.addEventListener('copy', copyHandler))
onUnmounted(() => unref(target)?.removeEventListener('copy', copyHandler))
}
使用方法
<script setup>
const ele = ref()
const watermark = `<br/>
<p>————————————————</p>
<p>版权声明:本文为 blyrin 的原创文章,禁止一切未经授权的转载、发布、出售等行为,违者将被追究法律责任。</p>
<p>原文链接:<a href="https://example.org/abc">https://example.org/abc</p></a>`
useCopyWatermark(ele, { watermark })
</script>
<template>
<div ref="ele"></div>
</template>
Node.js 笔记
文章最后更新:2023-08-02

快速升级依赖
下列内容来自 ChatGPT 3.5
要快速升级已有的 package.json 文件中的依赖版本,可以按照以下步骤进行操作:
- 打开你的项目文件夹,在命令行终端中导航到该文件夹的路径。
- 运行
npm outdated命令,它将显示项目中过时的依赖项及其当前版本和最新版本。这将帮助你确定需要升级的依赖项。 - 根据
npm outdated的输出,确定你想要升级的依赖项。你可以选择升级所有过时的依赖项,或者只升级你感兴趣的特定依赖项。 - 运行
npm update <package-name>命令来升级特定的依赖项。将<package-name>替换为你要升级的依赖项的名称。如果你要升级多个依赖项,可以在命令中列出它们的名称,用空格分隔。 例如:npm update package1 package2 package3 - 运行
npm install命令来安装更新后的依赖项。这将根据package.json文件中的新版本信息来安装依赖项。 - 检查项目是否正常工作。有时,升级依赖项可能会导致项目出现问题。确保在升级后运行项目并进行测试,以确保一切正常。
请注意,升级依赖项可能会引入不兼容的更改,因此在升级之前最好先备份你的项目文件。此外,如果你的项目使用了锁定版本的机制(例如
package-lock.json 或 yarn.lock),请确保在升级依赖项之前更新这些锁定文件,以便正确解析依赖项的版本。
GC 引擎
Chromium 和 Node.js 的 V8 引擎中的 GC (Garbage Collector) 引擎。
分代结构
在 V8 中,堆空间会被分成两块区域,或者叫代(generation),分别叫做新生代(young generation)和老年代(old generation) ,而新生代由分为托儿所(nursery)和中间代(intermediate)。
GC 流程
Minor GC (Scavenger)
Minor GC 主要针对新生代进行垃圾回收。在这个过程中,主要有三个步骤:移动对象、清空托儿所和角色互换。
移动对象
在 Minor GC 过程中,V8 会检查新生代中的对象,将存活的对象移动到中间代或老年代。这样可以确保新生代中的空间得到充分利用,同时减少内存碎片。
如果对象是第一次被移动,会移动到中间带,并打上标记,在下一次移动时,被标记的对象会被直接移动到老年代。
清空托儿所
在移动存活对象之后,V8 会清空托儿所,将其内存空间归还给操作系统。这样一来,新生代中的空间就可以重新分配给新创建的对象。
角色互换
清空托儿所后,中间代和托儿所的角色会发生互换,原先的中间代会变成托儿所,托儿所会变成中间代。
Major GC (Mark Sweep & Mark Compack)
Major GC 主要针对老年代进行垃圾回收。这个过程主要包括三个步骤:GC ROOT、并发标记和并发清除与整理。
GC ROOT
在 Major GC 开始时,V8 会首先确定一组根对象(GC ROOT),这些对象是不会被垃圾回收的。通过遍历这些根对象,V8 可以找出所有与之相关的存活对象。
并发标记
在这个阶段,V8 会并行地遍历整个堆空间,标记出所有存活的对象。这个过程可以在 JavaScript 执行过程中并发进行,从而降低垃圾回收对应用程序性能的影响。
并发清除和整理
最后,V8 会清除那些没有被标记为存活的对象,并整理堆空间。这样可以确保内存空间得到充分利用,同时减少内存碎片。
Go 语言笔记
文章最后更新:2023-08-02

Fiber 使用 JWT 登录验证
创建 项目
mkdir go-fiber-jwt
cd go-fiber-jwt
go mod init go-fiber-jwt
安装相关依赖
go get github.com/gofiber/fiber/v2
go get github.com/gofiber/contrib/jwt
编写 JWT 校验中间件
// jwt.go
package main
import (
jwtware "github.com/gofiber/contrib/jwt"
"github.com/gofiber/fiber/v2"
)
// Protected jwt 校验中间件
func Protected() fiber.Handler {
return jwtware.New(jwtware.Config{
SigningKey: jwtware.SigningKey{Key: []byte("JWT密钥")},
ErrorHandler: jwtError,
})
}
// jwt 校验错误处理器
func jwtError(c *fiber.Ctx, _ error) error {
return c.Status(fiber.StatusUnauthorized).SendStren("缺少 JWT 或 JWT 格式错误")
}
编写登录处理器
// login.go
package main
import (
"fmt"
"github.com/gofiber/fiber/v2"
"github.com/golang-jwt/jwt/v5"
"time"
)
// LoginRequest 登录请求
type LoginRequest struct {
Username string `json:"username"`
Password string `json:"password"`
}
// Login 登录获取 token
func Login(ctx *fiber.Ctx) error {
var err error
loginRequest := LoginRequest{}
// 获取登录请求体
err = ctx.BodyParser(&loginRequest)
if err != nil {
return err
}
// TODO 检查用户名密码
// 生成 token 返回
jwts := jwt.New(jwt.SigningMethodHS256)
claims := jwts.Claims.(jwt.MapClaims)
claims["username"] = loginRequest.Username
// 过期时间
claims["exp"] = time.Now().Add(time.Hour * 24).Unix()
token, err := jwts.SignedString([]byte("JWT密钥"))
if err != nil {
return err
}
return ctx.SendString(token)
}
注册中间件和处理器
// main.go
package main
import (
"github.com/gofiber/fiber/v2"
"log"
"time"
)
func main() {
app := fiber.New()
// 设置路由
app.Get("/login", Login)
// 需要保护的路由添加中间件即可
app.Get("/hello", Protected(), func(ctx *fiber.Ctx) error {
return ctx.SendString("hello")
})
// 启动
log.Fatal(app.Listen(":8080"))
}
操作 Minio
Minio 官方提供了 Go 的 SDK,可以使用下列指令安装:
go get github.com/minio/minio-go/v7
并且提供了对应的文档:https://min.io/docs/minio/linux/developers/go/API.html
Go SDK 基本使用
初始化上下文和客户端:
package main
import (
"context"
"log"
"github.com/minio/minio-go/v7"
"github.com/minio/minio-go/v7/pkg/credentials"
)
func main() {
// 创建一个上下文,用于超时和取消等操作的处理,这里直接使用默认的实现
ctx := context.Background()
// 创建 minio 客户端
endpoint := "127.0.1:9000"
id := "admin"
secret := "adminadmin"
SessionToken := ""
minioClient, err := minio.New(endpoint, &minio.Options{
Creds: credentials.NewStaticV4(id, secret, SessionToken),
})
if err != nil {
log.Fatalln(err)
}
// ...
}
上传文件:
func main() {
// ...
// 上传本地文件
bucketName := "test"
objectName := "123.jpg"
filePath := "test.jpg"
info, err := minioClient.FPutObject(ctx, bucketName, objectName, filePath, minio.PutObjectOptions{})
if err != nil {
log.Fatalln(err)
}
// 输出上传文件信息
log.Printf("上传完成\n%#v", info)
}
下载文件:
func main() {
// ...
// 下载文件到本地
bucketName := "test"
objectName := "123.jpg"
filePath := "456.jpg"
err = minioClient.FGetObject(ctx, bucketName, objectName, filePath, minio.GetObjectOptions{})
if err != nil {
log.Fatalln(err)
}
}
删除文件:
func main() {
// ...
// 删除文件
bucketName := "test"
objectName := "123.jpg"
err = minioClient.RemoveObject(ctx, bucketName, objectName, minio.RemoveObjectOptions{})
}
使用 Gin 框架进行服务器文件上传和下载
安装 Gin 框架:
go get github.com/gin-gonic/gin
完整代码:
package main
import (
"context"
"github.com/gin-gonic/gin"
"log"
"net/http"
"github.com/minio/minio-go/v7"
"github.com/minio/minio-go/v7/pkg/credentials"
)
func main() {
// 创建一个上下文,用于超时和取消等操作的处理,这里直接使用默认的实现
ctx := context.Background()
// 创建 minio 客户端
endpoint := "127.0.1:9000"
id := "admin"
secret := "adminadmin"
SessionToken := ""
bucketName := "test"
minioClient, err := minio.New(endpoint, &minio.Options{
Creds: credentials.NewStaticV4(id, secret, SessionToken),
})
if err != nil {
log.Fatalln(err)
}
// 创建 gin 路由
router := gin.Default()
// 文件上传
router.POST("/upload", func(c *gin.Context) {
// 读取文件
file, _ := c.FormFile("file")
reader, _ := file.Open()
defer func() {
// 关闭流
_ = reader.Close()
}()
// 上传到 minio
object, _ := minioClient.PutObject(ctx, bucketName, file.Filename, reader, file.Size, minio.PutObjectOptions{})
// 返回上传文件的信息
c.JSON(http.StatusOK, object)
})
// 文件下载
router.GET("/file/:name", func(c *gin.Context) {
name := c.Param("name")
// 读取文件
object, _ := minioClient.GetObject(ctx, bucketName, name, minio.GetObjectOptions{})
defer func() {
// 关闭流
_ = object.Close()
}()
// 返回文件
c.DataFromReader(http.StatusOK, -1, "application/stream", object, nil)
})
// 监听 8080
_ = router.Run(":8080")
}
使用 Fiber 框架进行服务器文件上传和下载
安装 Fiber 框架:
go get github.com/gofiber/fiber/v2
完整代码:
package main
import (
"context"
"github.com/gofiber/fiber/v2"
"github.com/gofiber/fiber/v2/utils"
"github.com/minio/minio-go/v7"
"github.com/minio/minio-go/v7/pkg/credentials"
"log"
)
func main() {
// 创建一个上下文,用于超时和取消等操作的处理,这里直接使用默认的实现
ctx := context.Background()
// 创建 minio 客户端
endpoint := "127.0.1:9000"
id := "admin"
secret := "adminadmin"
SessionToken := ""
bucketName := "test"
minioClient, err := minio.New(endpoint, &minio.Options{
Creds: credentials.NewStaticV4(id, secret, SessionToken),
})
if err != nil {
log.Fatalln(err)
}
// 创建 fiber 路由
app := fiber.New()
// 文件上传
app.Post("/upload", func(c *fiber.Ctx) error {
// 读取文件
file, err := c.FormFile("file")
if err != nil {
return err
}
reader, err := file.Open()
if err != nil {
return err
}
defer func() {
// 关闭流
_ = reader.Close()
}()
// 上传到 minio
filename := utils.UUID()
contentType := file.Header["Content-Type"][0]
object, err := minioClient.PutObject(ctx, bucketName, filename, reader, file.Size, minio.PutObjectOptions{
ContentType: contentType,
})
if err != nil {
return err
}
// 返回上传文件的信息
return c.JSON(object)
})
// 文件下载
app.Get("/file/:name", func(c *fiber.Ctx) error {
name := c.Params("name", "")
// 读取文件
object, err := minioClient.GetObject(ctx, bucketName, name, minio.GetObjectOptions{})
if err != nil {
return err
}
// 返回文件
return c.SendStream(object)
})
// 监听 8080
log.Fatal(app.Listen(":8080"))
}
Kotlin 笔记
文章最后更新:2023-09-27

Kotlin 扩展函数封装 bean 复制方法
封装了两个扩展函数,指定返回值类型即可快速拷贝字段
直接上代码:
/**
* 扩展 [T].[copy],指定返回值类型 [R] 即可快速获取对象拷贝
*
* 使用方法:val xxxDto: [R] = xxx.copy()
*
*/
inline fun <T : Any, reified R : Any> T.copy(): R {
// 获取返回类型的 class
val clazz = R::class.java
// 获取构造函数
val constructor = clazz.declaredConstructors.first()
// 构建目标对象
val instance = constructor.newInstance() as R
// 复制属性 (这里使用的是spring自带的 可以换成其他的工具)
BeanUtils.copyProperties(this, instance)
return instance
}
/**
* 扩展 [T].[copy],指定返回值类型 [R] 即可快速获取对象拷贝
*
* 使用方法:val xxxDto: [R] = xxx.copy { ... }
*
*/
inline fun <T : Any, reified R : Any> T.copy(after: (R.() -> Unit)): R {
val instance: R = this.copy()
instance.after()
return instance
}
测试一下
class Student {
var id: Int? = null
var name: String? = null
}
class StudentDto {
var id: Int? = null
var name: String? = null
}
fun main() {
val stu = Student().apply {
id = 123
name = "张三"
}
// 指定变量类型即可复制
val stuDto: StudentDto = stu.copy {
println("复制完成")
name = "wdnmd"
}
println(stuDto.name)
}
在 Kotlin 中使用 SLF4J
Java 中的 Logger
众所周知,在 Java 中我们可以使用静态属性和静态方法来快速获取当前类的 slf4j 的日志对象
private static final Logger log = LoggerFactory.getLogger(Example.class);
Kotlin 伴生对象获取 Logger
但是在 kotlin 中是没有静态属性和静态方法这个说法的
我们可以利用 kotlin 的伴生对象来完成类似的功能,但是这样每次都要写很多代码,不够优雅
class Example {
companion object {
@JvmStatic
private val log: Logger = LoggerFactory.getLogger(this::class.java)
}
fun test() {
log.info("...")
}
}
Kotlin 通过委托获取 Logger
可以利用 kotlin 的委托,并且能把对象创建进行延迟,使用方法也很简单
写一个委托类:
/**
* slf4j 日志对象获取委托类
*/
class LoggerDelegate : ReadOnlyProperty<Any, Logger> {
/**
* 延迟创建的单例日志
*/
private var _logger: Logger? = null
/**
* 获取单例 logger
*/
override operator fun getValue(thisRef: Any, property: KProperty<*>): Logger {
if (_logger != null) return _logger!!
// 获取 logger 对象,由 LoggerFactory 底层保证线程安全
_logger = LoggerFactory.getLogger(thisRef::class.java)
return _logger!!
}
}
使用案例:
class Example {
private val log by LoggerDelegate()
fun test() {
log.info("...")
}
}
Spring Security 使用 JWT 登录认证
使用 Oauth2 Resource Server 的 JWT 进行登录认证
配置依赖
implementation("org.springframework.boot:spring-boot-starter-security")
implementation("org.springframework.boot:spring-boot-starter-oauth2-resource-server")
配置 Spring Security
@Configuration(proxyBeanMethods = false)
@EnableWebSecurity
class SecurityConfig {
private companion object {
// 生成随机的 RSA 密钥对用于 jwt 签名,重启服务器旧密钥即失效
private val keyPair by lazy {
val generator = KeyPairGenerator.getInstance("RSA")
// 每次生成的密钥不一样,如果想保证一致,可以在第二个参数添加固定的随机种子
generator.initialize(2048)
generator.generateKeyPair()
}
}
/**
* jwt 生成器
*/
@Bean
fun jwtEncoder(): JwtEncoder {
val key = RSAKey
.Builder(keyPair.public as RSAPublicKey)
.privateKey(keyPair.private)
.build()
val jwkSet = ImmutableJWKSet<SecurityContext>(JWKSet(key))
return NimbusJwtEncoder(jwkSet)
}
/**
* jwt 解码器
*/
@Bean
fun jwtDecoder(): JwtDecoder = NimbusJwtDecoder
.withPublicKey(keyPair.public as RSAPublicKey)
.build()
/**
* 密码加解密器
*/
@Bean
fun passwordEncoder() = BCryptPasswordEncoder()
/**
* 提供认证管理器的 Bean
*/
@Bean
fun authenticationManager(config: AuthenticationConfiguration): AuthenticationManager =
config.getAuthenticationManager()
@Bean
fun securityFilterChain(http: HttpSecurity): SecurityFilterChain = with(http) {
// 关闭 csrf
csrf { it.disable() }
// 关闭 session
sessionManagement { it.sessionCreationPolicy(SessionCreationPolicy.STATELESS) }
// 开启 jwt token 验证
oauth2ResourceServer { it.jwt {} }
authorizeHttpRequests {
it.anyRequest().authenticated()
}
// 其他配置...
http.build()
}
// 其他配置和 Bean ...
}
编写 token 生成接口
@RestController
@RequestMapping("/auth")
class AuthController(
private val authenticationManager: AuthenticationManager,
private val jwtEncoder: JwtEncoder
) {
/**
* 登录返回 token
*/
@PostMapping
fun login(@RequestBody @Validated loginRequest: LoginRequest): RestResult<String?> {
// 登录认证
val authToken = UsernamePasswordAuthenticationToken(loginRequest.username, loginRequest.password)
authenticationManager.authenticate(authToken)
// 生成 token
val now = Instant.now()
val claimsSet = JwtClaimsSet.builder() // 设置 token 生成时间
.issuedAt(now) // 设置 token 过期时间 7 天
.expiresAt(now.plusSeconds(604800))
.subject(loginRequest.username)
// 其他配置
.build()
// 返回 token
return jwtEncoder
.encode(JwtEncoderParameters.from(claimsSet))
.tokenValue.restOk()
}
}
data class LoginRequest(
val username: String,
val password: String
)
ungoogled chromium 安装配置
文章最后更新:2024-03-03

介绍
ungoogled-chromium 是基于 Chromium 的衍生版本,代码同样开源。相比起 Chromium,其剥离了所有来自 Google 的网络服务组件,进一步屏蔽 Google 内置于浏览器中的各种数据收集行为(比如: Google Safe Browsing API 会收集你浏览的所有网站地址用于恶意网址识别)。
-
彻底移除了 Google 服务相关组件,ungoogled-chromium 无法在线安装 Chrome 扩展插件,后文将提供解决方法。
-
ungoogled-chromium 移除了自动更新功能,你可以根据自己的使用习惯,择期对软件进行更新。
官网:https://ungoogled-software.github.io/ Github:https://github.com/ungoogled-software/ungoogled-chromium
安装方法
Windows
只支持 x86、x86_64 架构。
下载链接:https://github.com/ungoogled-software/ungoogled-chromium-windows/releases
Linux
OpenSUSE Tumbleweed
zypper in ungoogled-chromium
Arch Linux
仓库地址:https://github.com/ungoogled-software/ungoogled-chromium-archlinux
Fedora
# fedora 35
dnf config-manager --add-repo https://download.opensuse.org/repositories/home:/ungoogled_chromium/Fedora_35/home:ungoogled_chromium.repo
dnf install ungoogled-chromium
# fedora 34
dnf config-manager --add-repo https://download.opensuse.org/repositories/home:/ungoogled_chromium/Fedora_34/home:ungoogled_chromium.repo
dnf install ungoogled-chromium
手动下载安装:https://build.opensuse.org/project/show/home:ungoogled_chromium
其他 Linux
Flatpak
com.github.Eloston.UngoogledChromium
GNU Guix
ungoogled-chromium
NixOS/nixpkgs
ungoogled-chromium
MacOS
通过 brew 安装:
brew install --cask eloston-chromium
手动安装:https://github.com/ungoogled-software/ungoogled-chromium-macos/releases
其他系统
上述未列出的系统,可以通过下方链接下载:
https://ungoogled-software.github.io/ungoogled-chromium-binaries/
配置
修复在线扩展问题
- 浏览器打开地址
chrome://flags/#extension-mime-request-handling,修改为[Always prompt for install]; - 下载扩展 https://github.com/NeverDecaf/chromium-web-store/releases,将下载好的
.crx文件拖到chrome://extensions/页面安装; - chromium-web-store 可以自动检测插件版本,但无法自动更新插件,需要手动点击需要更新的插件进行安装。
如果 Chrome 的在线商城无法安装扩展,可借用 Edge 的来安装:https://microsoftedge.microsoft.com/addons
保留历史记录和 Cookie
ungoogled-chromium 在默认情况下,关闭浏览器时会清除所有网站的 Cookie。此举虽然能保护隐私,但是每次打开浏览器的时候都要重新登陆各种网站和服务,在实际使用中颇为不便。
在 chrome://settings/cookies 设置中将「常规设置」的选项修改为「在无痕模式下阻止第三方 Cookie」。
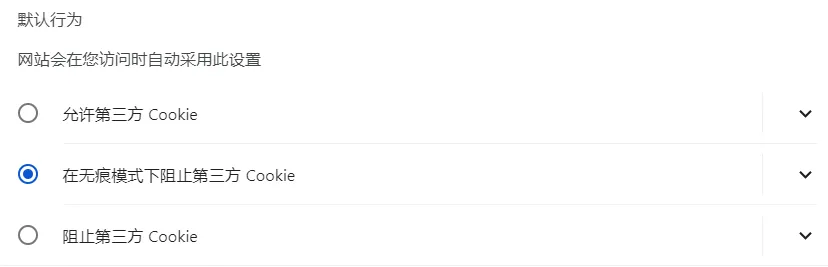
设置 chrome://flags/#keep-old-history 为 [Enable] 以保留历史记录。

添加 Google 搜索
由于所有的 Google 服务被关闭,Google 搜索需要手动添加
- 打开
chrome://settings/searchEngines; - 点击添加网站搜索,按照下方内容填写
- 搜索引擎:Google
- 快捷字词:google.com
- 网址格式:
https://www.google.com/search?q=%s&{google:RLZ}{google:originalQueryForSuggestion}{google:assistedQueryStats}{google:searchFieldtrialParameter}{google:iOSSearchLanguage}{google:prefetchSource}{google:searchClient}{google:sourceId}{google:contextualSearchVersion}ie={inputEncoding} - 推荐地址:
https://www.google.com/complete/search?client=chrome&q=%s - 保存后设置为默认搜索引擎即可
Flags 设置
打开 chrome://flags/ 搜索对应的选项。
已在 Windows 11 22H2 x86_64,ungoogled-chromium v122.0.6261.69 下测试正常。
推荐选项
| 选项 | 说明 |
|---|---|
| #show-avatar-button | [Disabled] 隐藏用户按钮 |
| #remove-tabsearch-button | [Enabled] 可以隐藏搜索标签页按钮 |
| #disable-qr-generator | [Enabled] 可以隐藏地址栏中的二维码图标 |
| #disable-sharing-hub | [Enabled] 可以隐藏地址栏中的分享图标 |
| #hide-sidepanel-button | [Enabled] 可以隐藏浏览器侧边栏/阅读列表 |
| #chrome-labs | [Enabled] 去除实验室图标 |
| #enable-tab-audio-muting | [Enabled] 标签页静音功能 |
| #scroll-tabs | [Enabled] 滚轮切换标签 |
| #custom-ntp | [Enabled] 修改新标签地址(修改为 chrome://new-tab-page 即可修改主题) |
| #smooth-scrolling | [Enabled] 平滑滚动 |
| #windows-scrolling-personality | [Enabled] 修复 Windows 下滚动不流畅问题 |
| #remove-tabsearch-button | [Enabled] 去除标签搜索按钮 |
| #enable-parallel-downloading | [Enabled] 启用多线程下载 |
| #chrome-refresh-2023 | [Enabled] 新的 Chrome UI (需要同时开启) |
| #chrome-webui-refresh-2023 | [Enabled] 新的 Chrome UI (需要同时开启) |
| #customize-chrome-side-panel | [Enabled] 新的 Chrome UI (需要同时开启) |
| #fluent-scrollbars | [Enabled] win11 风格的滚动条(需要系统支持) |
| #windows11-mica-titlebar | [Enabled] Win11 Mica 风格透明标题栏(需要系统支持) |
其他选项
警告:下列选项请根据需要酌情使用!
| 选项 | 说明 |
|---|---|
| #temporary-unexpire | [Enabled] 使所有暂时失效的选项重新可用 |
| #set-ipv6-probe-false | [Disabled] ipv6 探测 |
| #enable-quic | [Enabled] HTTP3 QUIC 协议支持 |
| #ignore-gpu-blocklist | [Enabled] 强制开启 GPU 加速 |
| #enable-gpu-rasterization | [Enabled] GPU 光栅化处理页面 |
| #zero-copy-video-capture | [Enabled] 零拷贝视频捕获 |
| #enable-zero-copy | [Enabled] 零拷贝光栅化 |
| #enable-drdc | [Enabled] GPU 合成器使用单独的线程 |
| #use-angle | [D3D11] ANGLE 图形后端(N 卡推荐 OpenGL,其他独显 D3D11on12,核显 D3D11) |
| #canvas-oop-rasterization | [Enabled] 在 GPU 进程中执行 Canvas 2D 光栅化 |
| #enable-oop-print-drivers | [Enabled] 使与操作系统的打印交互可以在进程外进行 |
| #enable-raw-draw | [Enabled] 启用 Raw Draw |
| #background-resource-fetch | [Enabled] 使用 Blink 后台引擎获取资源 |
| #ui-enable-shared-image-cache-for-gpu | [Enabled] 共享 GPU 图像解码缓存 |
| #enable-zstd-content-encoding | [Enabled] zstd 压缩格式 |
| #enable-shared-zstd | [Enabled] zstd 压缩格式 |
| #use-gpu-scheduler-dfs | [Enabled] 新的 GPU 调度器 |
| #use-client-gmb-interface | [Enabled] 使用新的 ClientGmb 接口创建 GPU 缓存 |
收藏夹和密码同步
由于 Google 全家桶无法使用,也就无法登录谷歌账号,这里我使用的是第三方收藏夹和密码同步插件。
WebDAV 和 BitWarden 均为服务器自建。
DRM 数字版权保护功能
使用 ungoogled-chromium 访问流媒体网站,可能会发现一些版权内容无法播放,特别是观看一些从国外进口的影视版权资源时,非常容易遇到这个问题。
播放该资源需要浏览器支持 DRM 数字版权保护技术,而 Chrome 数字版权保护所需的 Widevine 组件并没有随 Chromium 项目一同开源。Widevine 是 Google 于 2010 年收购的一种数字版权保护技术,作为组件内置于 Chrome 中。其本身用于加密/解密版权内容,未包含在 Chromium 开源项目内也情有可原。
可以打开页面 chrome://settings/content/protectedContent 检查 Widevine 组件是否有效。
解决思路也很简单,找到最新版 Widevine 组件、或者最新版本的 Chrome 安装包,把 Widevine 相关文件提取出来,「搬」到指定的文件路径中,重启浏览器即可恢复浏览器 DRM 数字版权保护功能。
- 下载版本文件:https://dl.google.com/widevine-cdm/versions.txt
- 根据上面的版本文件,根据系统下载最新版本的组件:
- https://dl.google.com/widevine-cdm/<版本号>-win-x64.zip
- https://dl.google.com/widevine-cdm/<版本号>-win-ia32.zip
- https://dl.google.com/widevine-cdm/<版本号>-mac-x64.zip
- https://dl.google.com/widevine-cdm/<版本号>-linux-x64.zip
- 进入
浏览器安装目录/<浏览器版本号>文件夹下(可以通过chrome://version/查看) - 按照下列结构放置插件
WidevineCdm (如果不存在则新建)
├── LICENSE.txt
├── manifest.json
│
├── _platform_specific
├── win_x64 (这个文件夹名需要根据你实际下载的决定)
├── widevinecdm.dll
├── widevinecdm.dll.lib
├── widevinecdm.dll.sig
- 重启浏览器,打开
chrome://components/可以找到对应的插件版本

VMware Workstation 下载地址
文章最后更新:2024-08-25

需要登录才能下载
https://support.broadcom.com/group/ecx/productdownloads?subfamily=VMware%20Workstation%20Pro